
实际上就是我们在一个复杂的地图中寻找一条能够从起点到达终点的路径。可以看到从起点开始,每到一个路口,可能都会出现多个分叉,可能有的分叉就会走进死胡同,有的分叉就会走到下一个路口。
那么我们人脑是怎么去寻找到正确的路径呢?
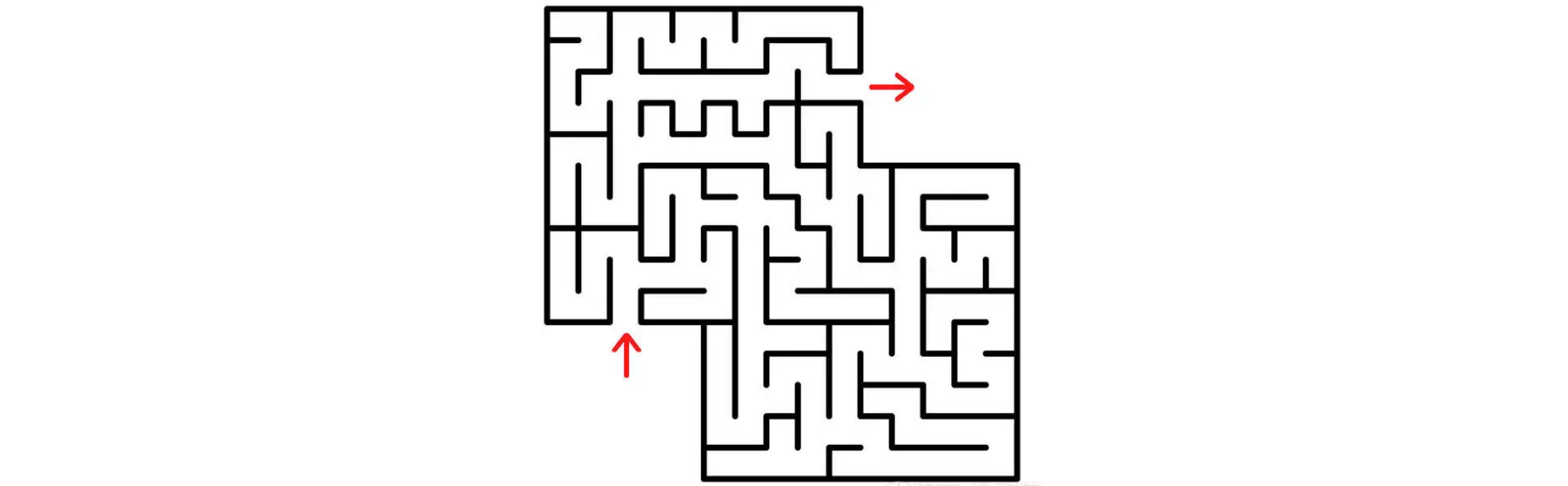
我们首先还是会从起点开始看,我们会尝试去走分叉路的每一个方向,如果遇到死胡同,那么我们就退回到上一个路口,再去尝试其他方向,直到能一直往下走为止。经过不断重复上述的操作,最后我们就肯定能够到达迷宫的出口了。
而图的搜索,实际上也是类似于迷宫这样的形式,我们需要从图的某一个顶点出发,去寻找到图中对应顶点的位置,这一部分,我们将对图的搜索算法进行讨论。
深度优先搜索(DFS)
什么是DFS
比如现在我们要从A开始寻找下图中的I:
那么我们的路线可以是这样的:
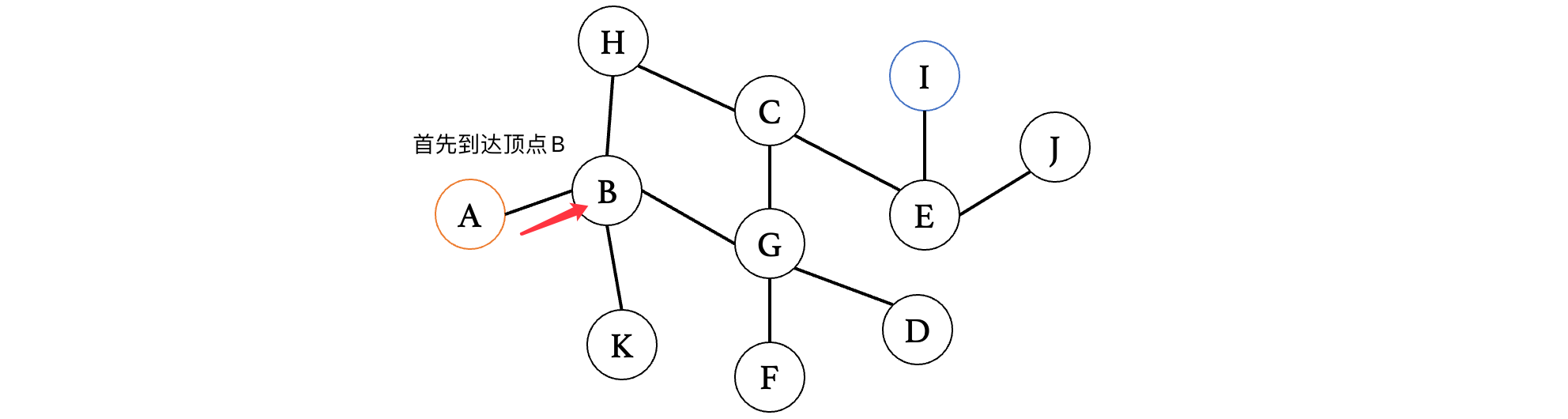
此时顶点B有三个方向,那么我们可以先随便选一个方向(当然,一般情况下为了规范,推荐按照字母排列顺序来走,这里为了演示,就随便走了)看看:
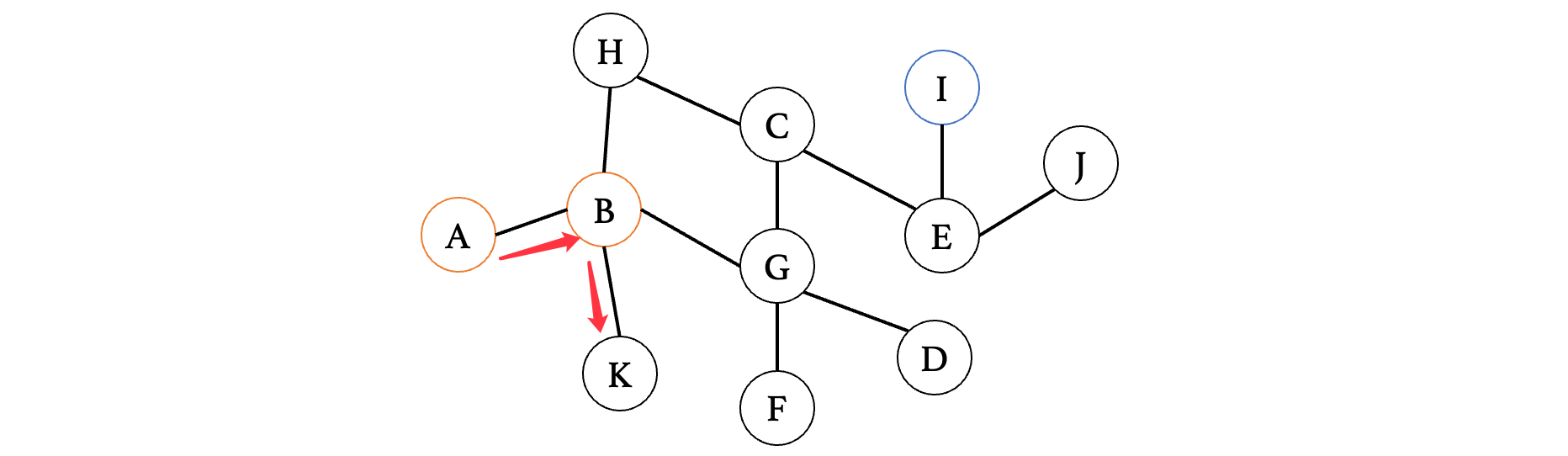
此时来到K,我们发现K已经是一个死胡同,没有其他路了,那么此时我们就需要回到上一个路口,继续去探索其他的路径:
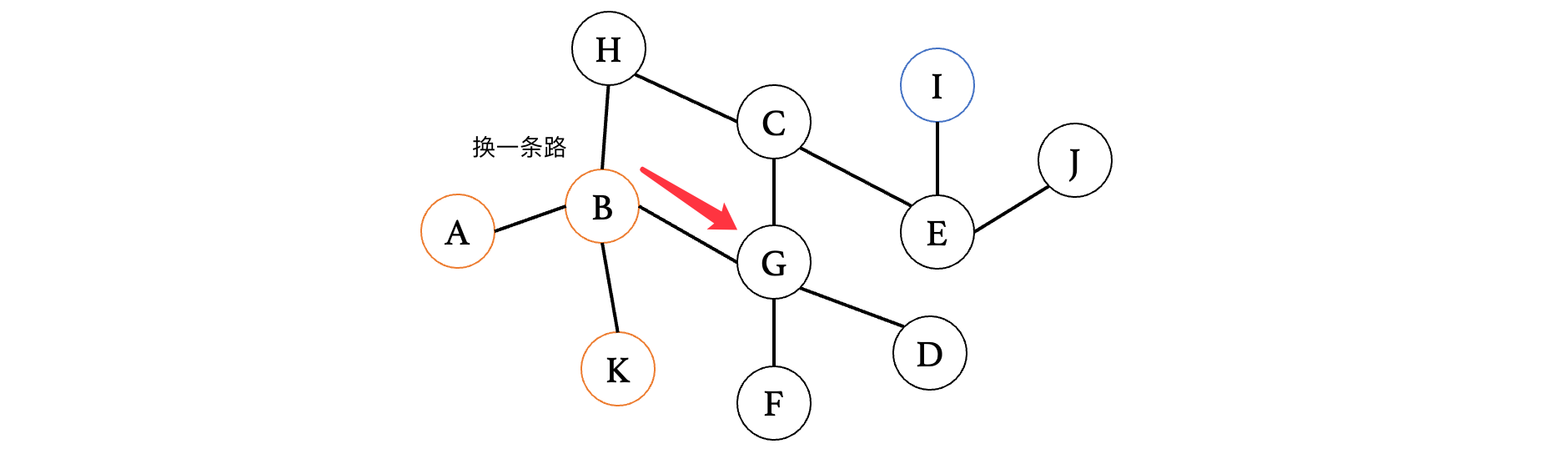
此时我们接着往下一个相邻的顶点G走,发现G有其他的分叉,那么我们就继续向前:
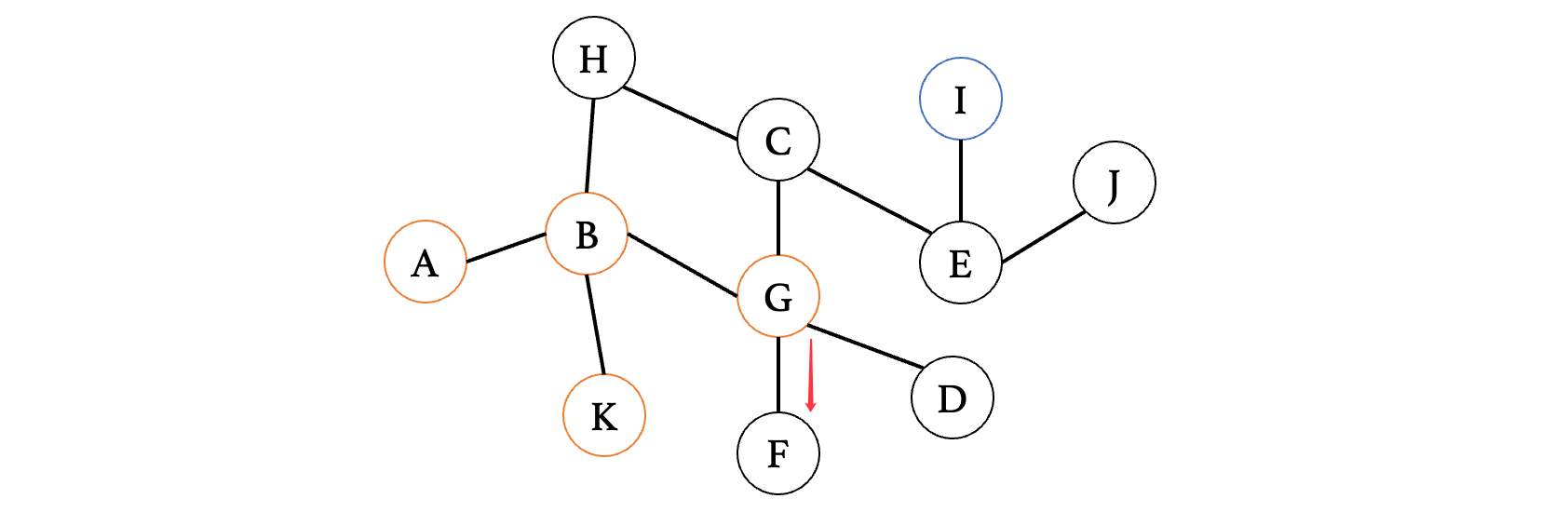
此时走到F发现又是死路,那么退回到G,走其他的方向:
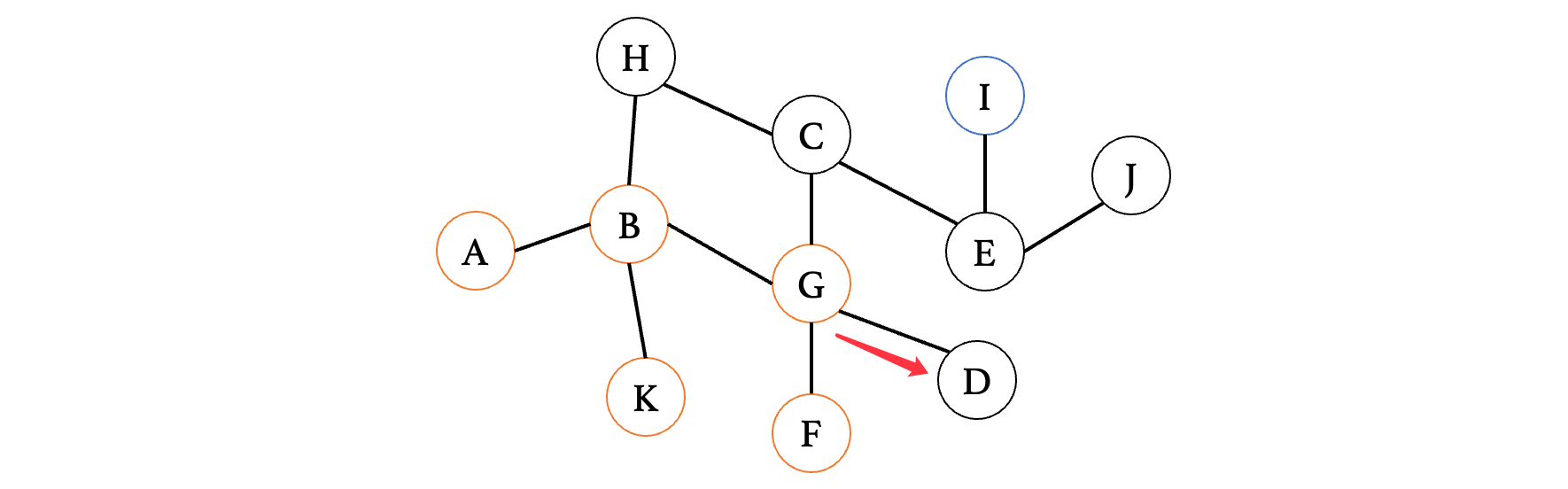
运气太垃了,又到死胡同了,同样的,回到G继续走其他方向:
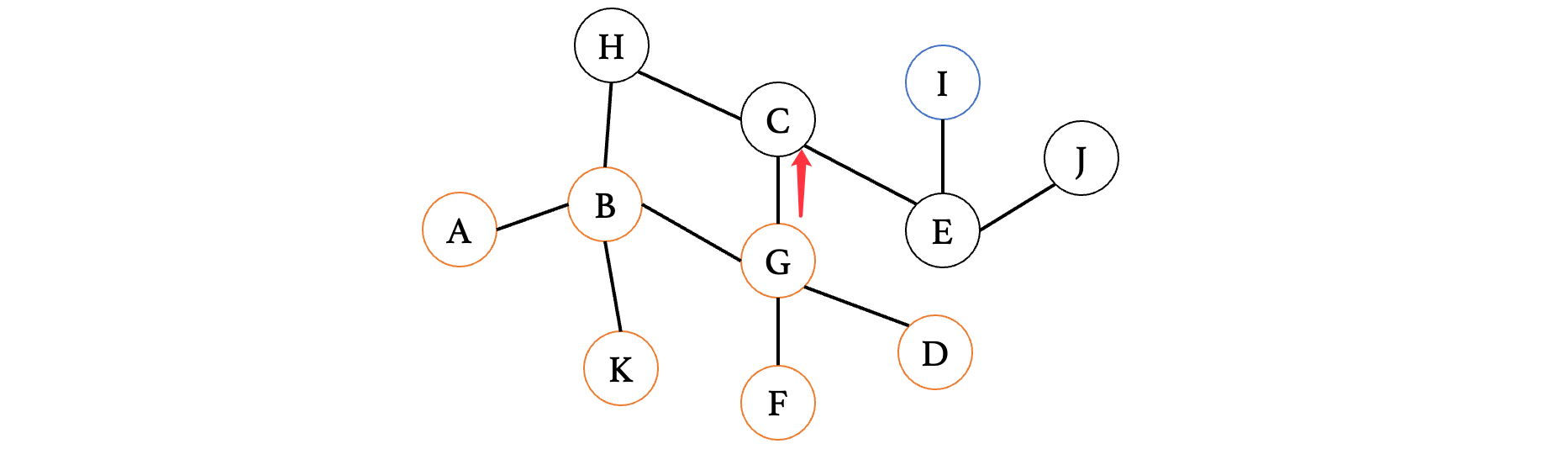
走到C之后,我们有其他的路,我们继续往后走:
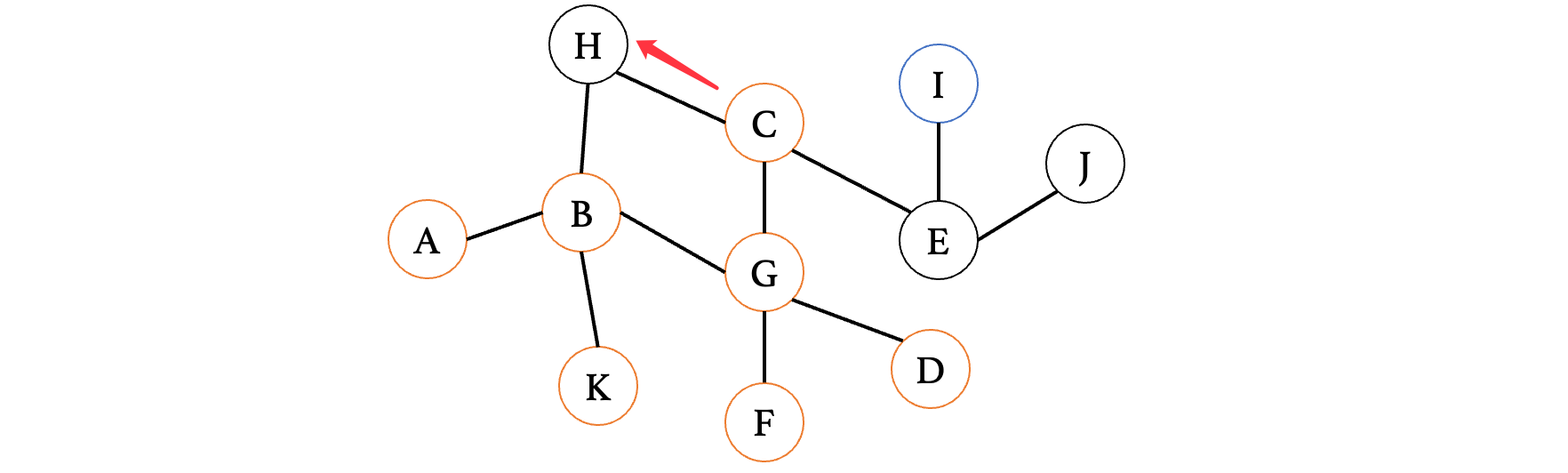
此时走到顶点H,发现H只有一条路,并且H再向前是已经走过的顶点B,那么此时不能再向前了,所以说直接退回到C,走另一边:
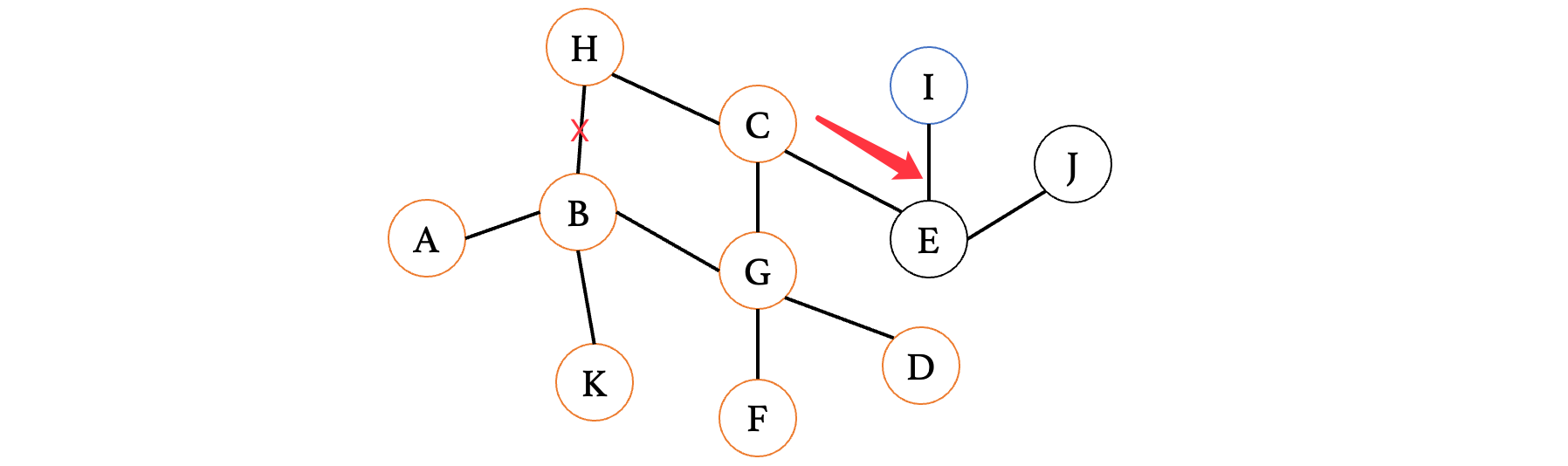
此时来到E,又有两条路,那么继续随便选一条走:
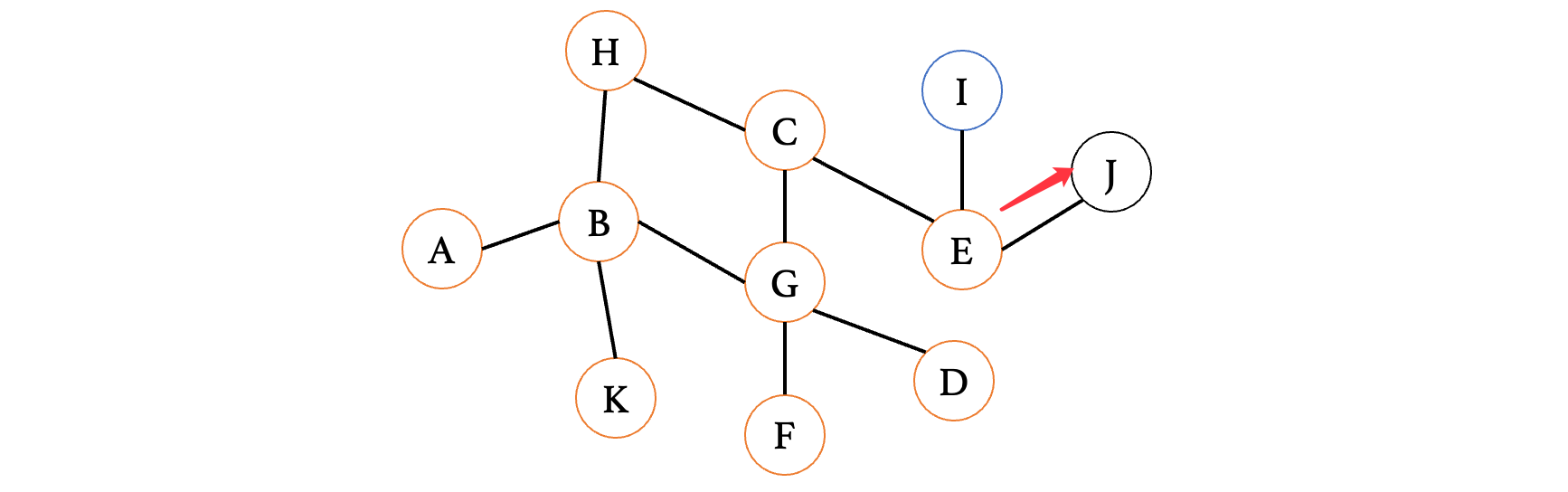
此时来到顶点J,发现又是死胡同,退回到E,继续走另一边:
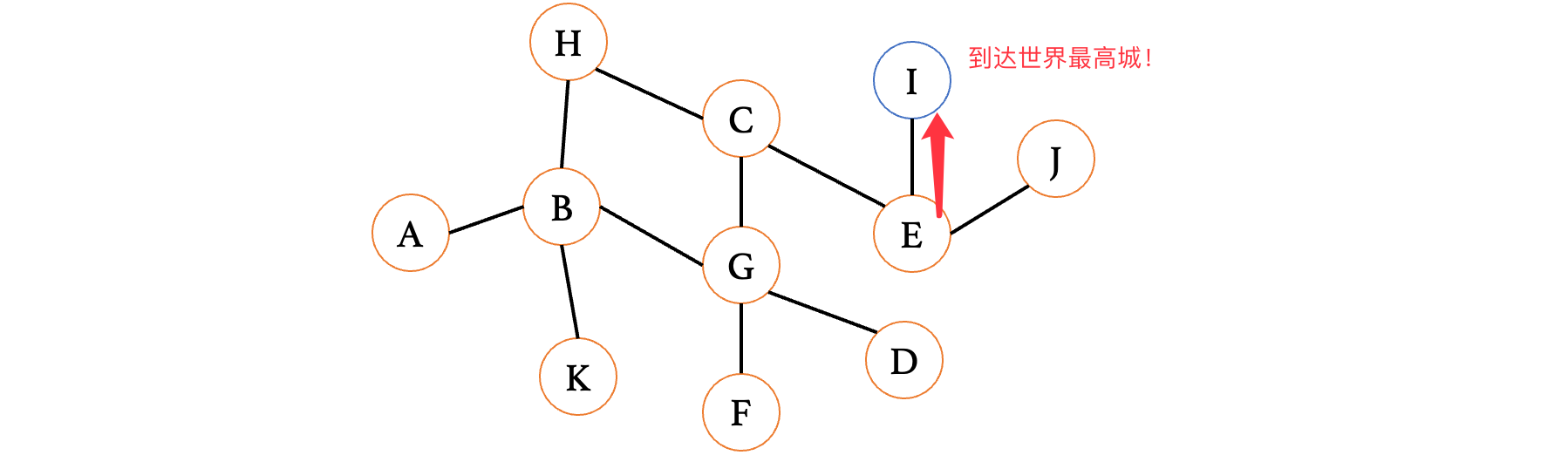
好了,经过了这么多试错,终于是找到了I顶点,这种方式就是深度优先搜索(DFS)了。
代码实操
初始化
那么我们就来打个代码玩玩吧,这里我们构建一个简单一点的图:
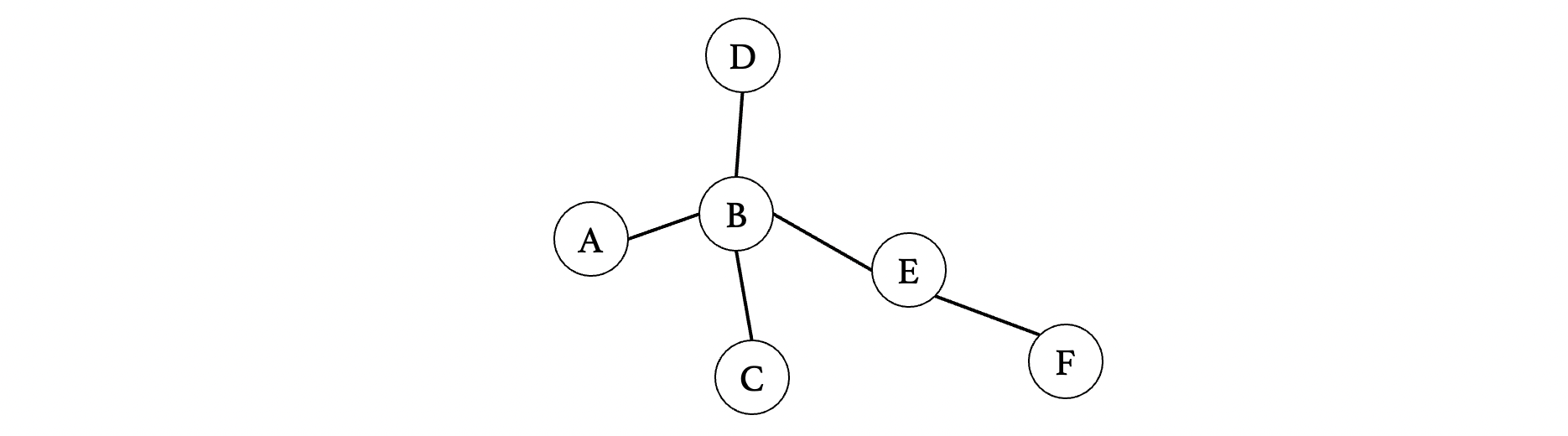
这里我们使用邻接表表示图,因为邻接表直接保存相邻顶点,所以说到达顶点时遍历相邻顶点会更快(能够到达 O(V+E)O(V+E) 线性阶)而如果使用邻接矩阵的话,我们得完整遍历整个二维数组,就比较费时间了(需要 O(V2)O(V2) 平方阶)。
比如现在我们想从A开始查找顶点F,首先先把图给建好(注意有6个顶点,记得容量写好):
1 | int main(){ |

搜索
然后就是我们的深度优先搜索算法了:
1 | /** |
我们先将深度优先遍历写出来:
1 | /** |
深度优先遍历结果如下:

路线如下:
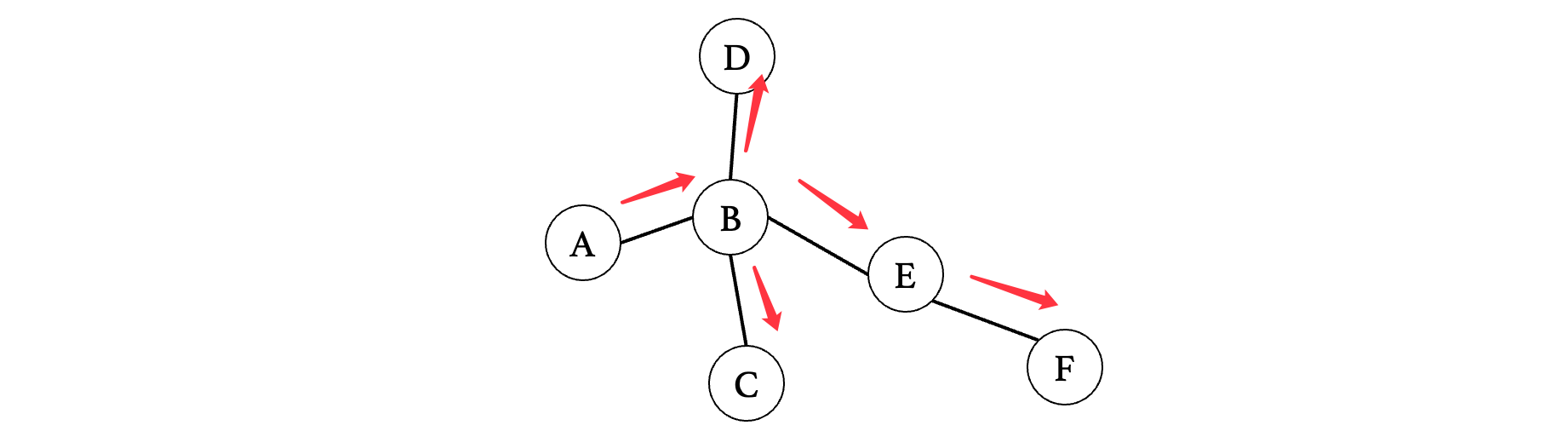
现在我们将需要查找的顶点进行判断:
1 | /** |
得到结果如下:

再来找一下顶点D呢:

可以看到到D之后就停止了,因为已经找到了。那么要是去寻找一个没有连接到图中的结点呢?

可以看到整个图按照深度优先遍历找完了都没找到。
广度优先搜索(BFS)
什么是BFS
前面我们介绍了深度优先搜索,我们接着来看另一种方案。还记得我们在前面二叉树中学习的层序遍历吗?
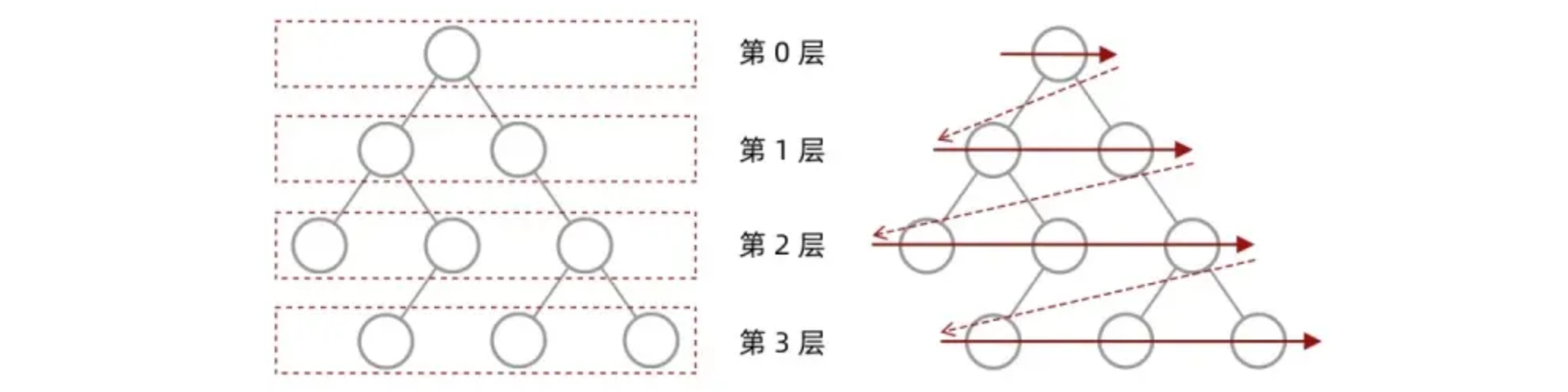
层序遍历实际上是优先将每一层进行遍历,而不是像前序遍历那样勇往直前,而图的搜索其实也可以采用这种方案,我们可以先探索顶点所有的分支,然后再依次去看这些分支的所有分支:
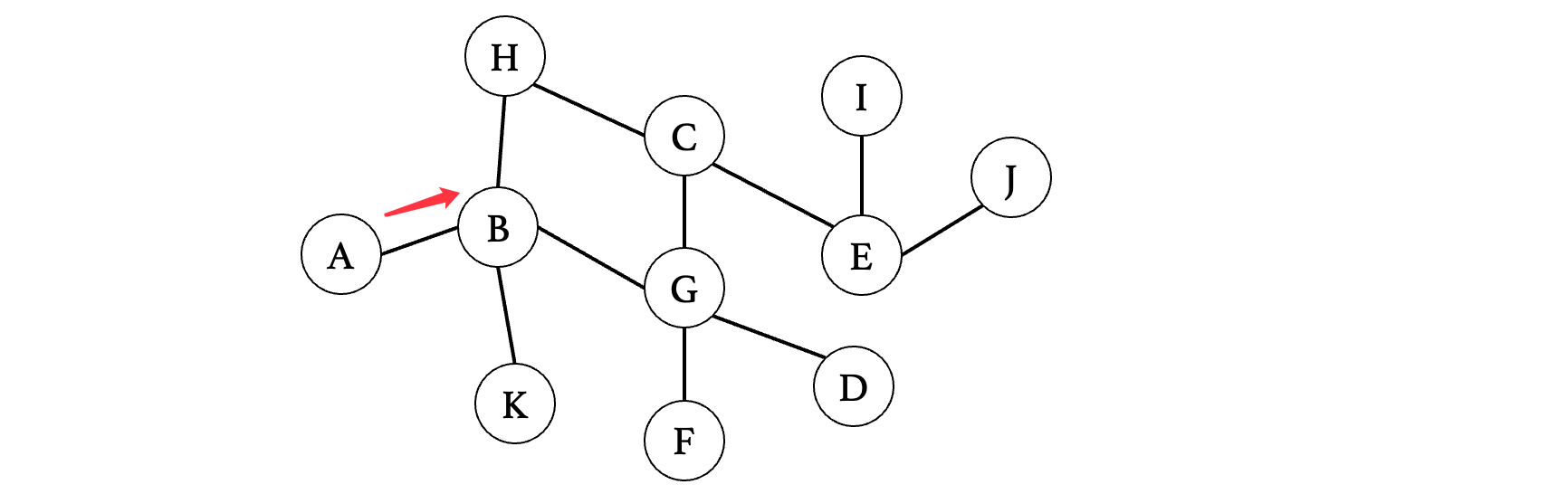
我们先记录一下这三个顶点,同样需要使用队列来完成:H、G、K
注意访问之后不要再继续向下了,接着我们从这三个里面的第一个顶点H开始,按照同样的方法继续:
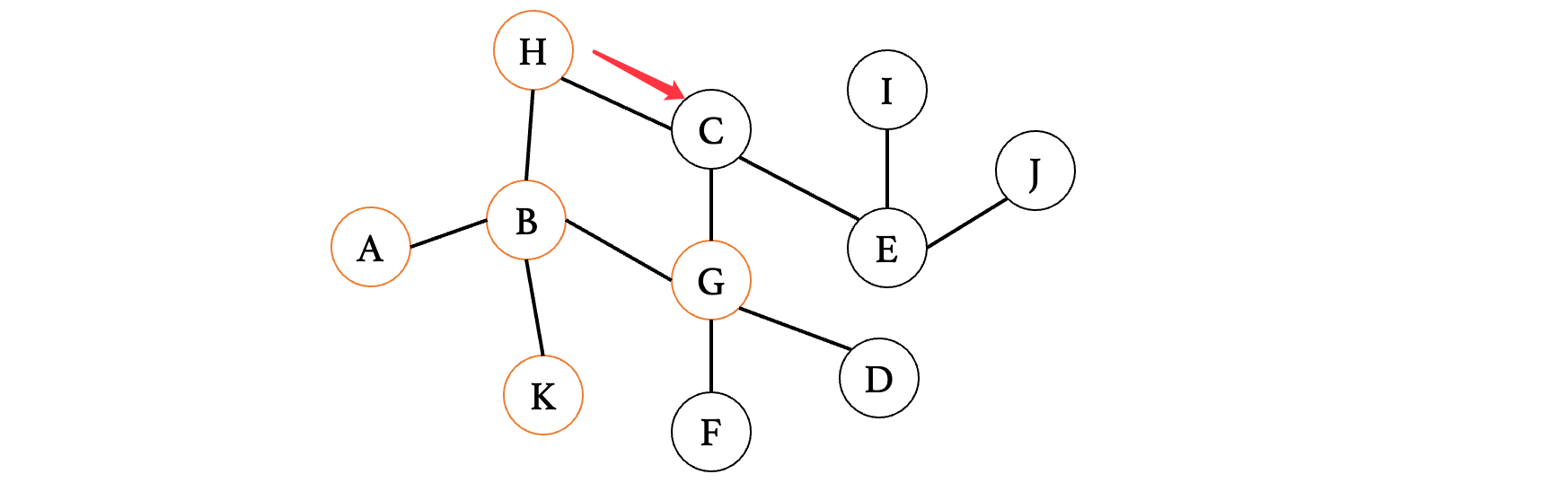
此时因为只有一个分支,所以说找到C,继续记录,将C也添加进去:G、K、C
注意此时需要回去,继续看之前三个顶点的第二个顶点G:
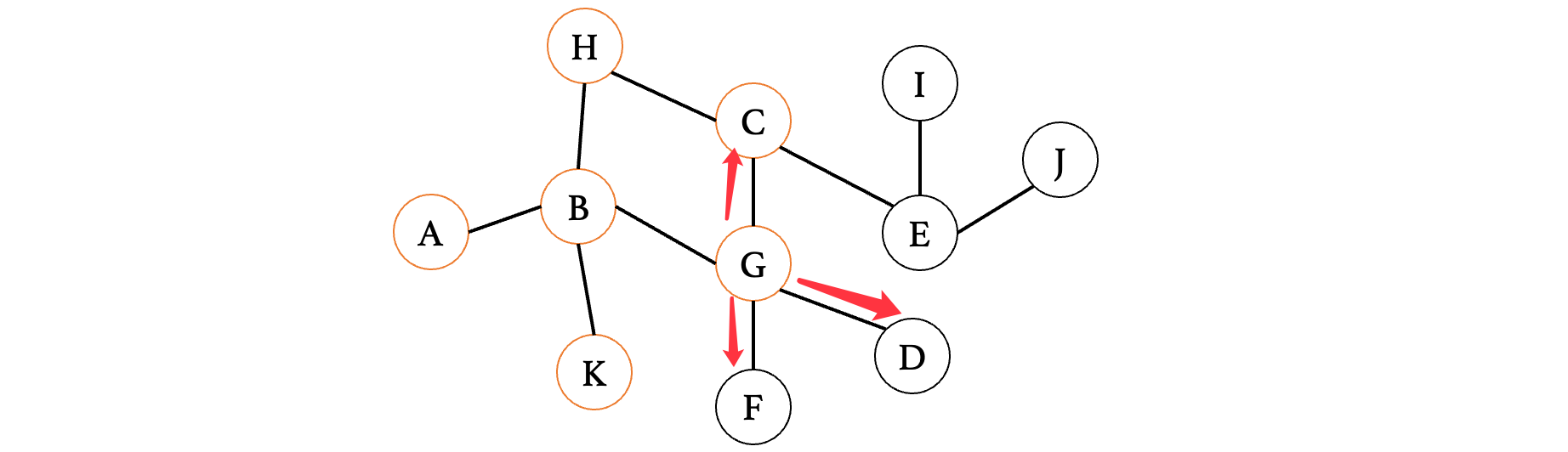
此时C已经看过了,接着就找到了F和D,也是记录一下:K、C、F、D
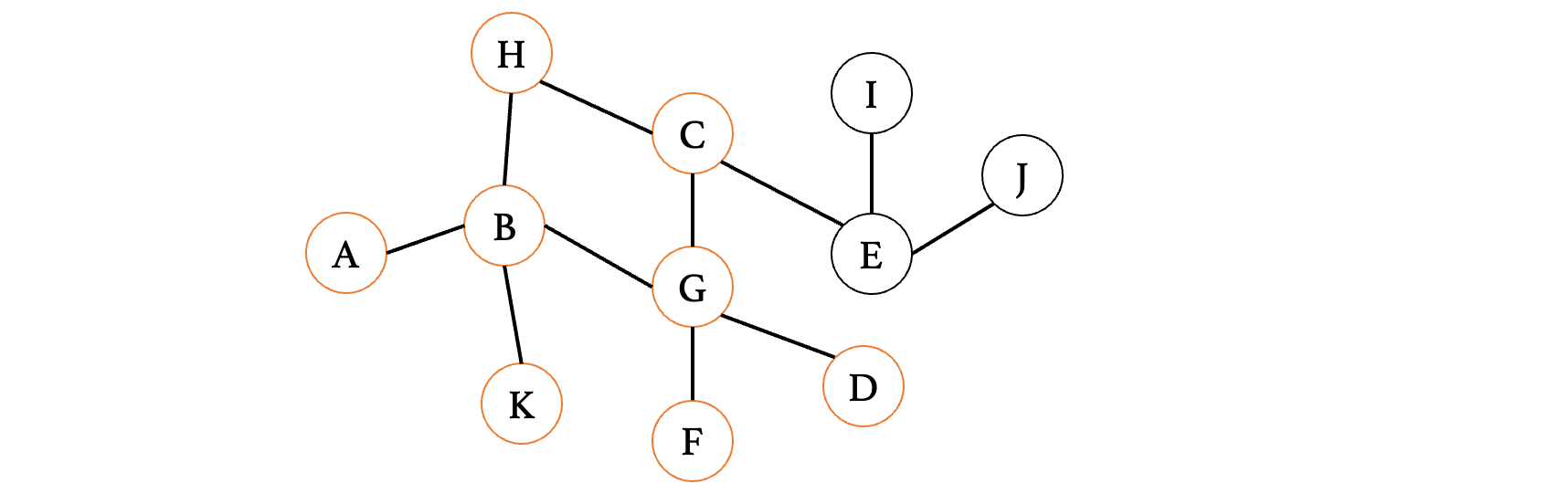
此时K已经是死胡同了,那么就结束,然后继续看下一个C:
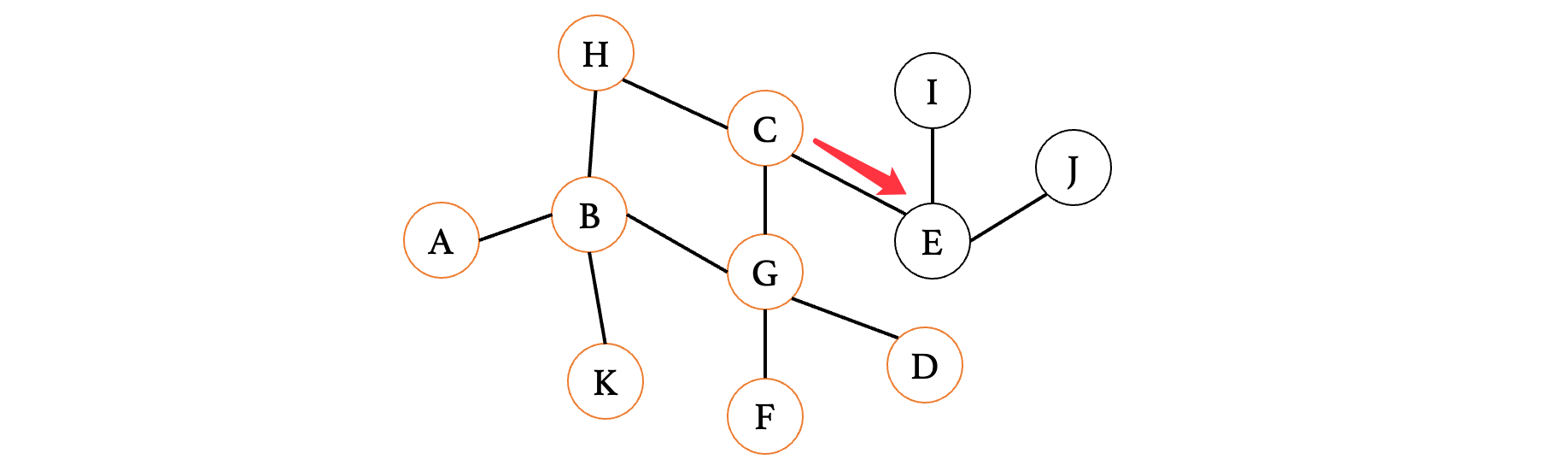
时继续将E给记录进去:F、D、E,接着看D和F,也没有后续了,那么最后就只有E了:
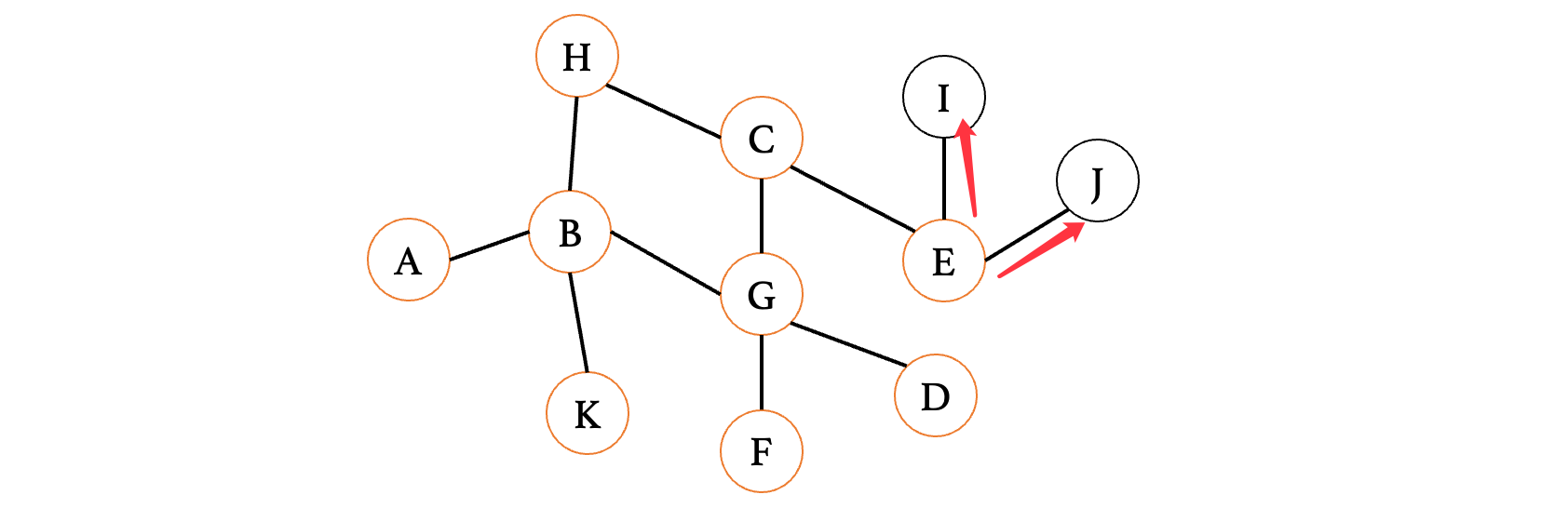
成功找到目标I顶点,实际上广度优先遍历就是尽可能地扩展范围,多去探索广阔的土地,而不是死拽着一根不放。
代码实现
那么按照这个思路,我们就来尝试代码实现一下,首先把队列搬过来:
1 | typedef int T; //这里将顶点下标作为元素 |
案例
我们还是以上面的图为例:
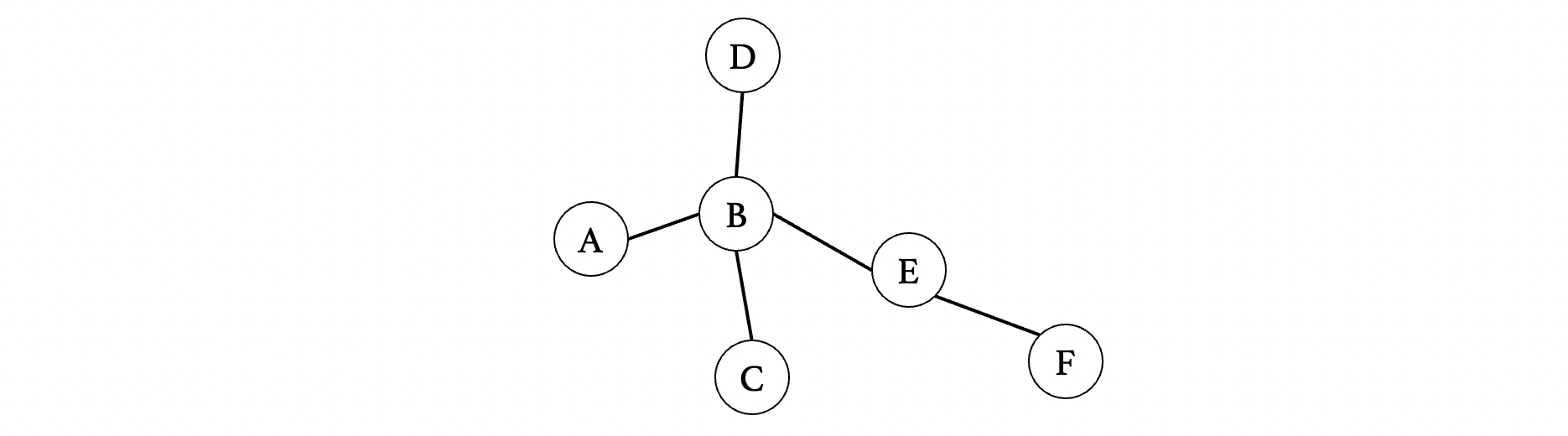
1 | /** |
我们来测试一下吧:
1 | int main(){ |
成功得到结果:

如果要指定查找的话,就更简单了:
1 | _Bool bfs(Graph graph, int startVertex, int targetVertex, int * visited, LinkedQueue queue) { |
这样,我们就实现了图的广度优先搜索。

说些什么吧!