
什么是哈夫曼树
各位了解文件压缩吗?它是怎么做到的呢?我们都会在这一节进行探讨。
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)
啥叫带权路径长度达到最小?就是树中所有的叶结点的权值乘上其到根结点根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)
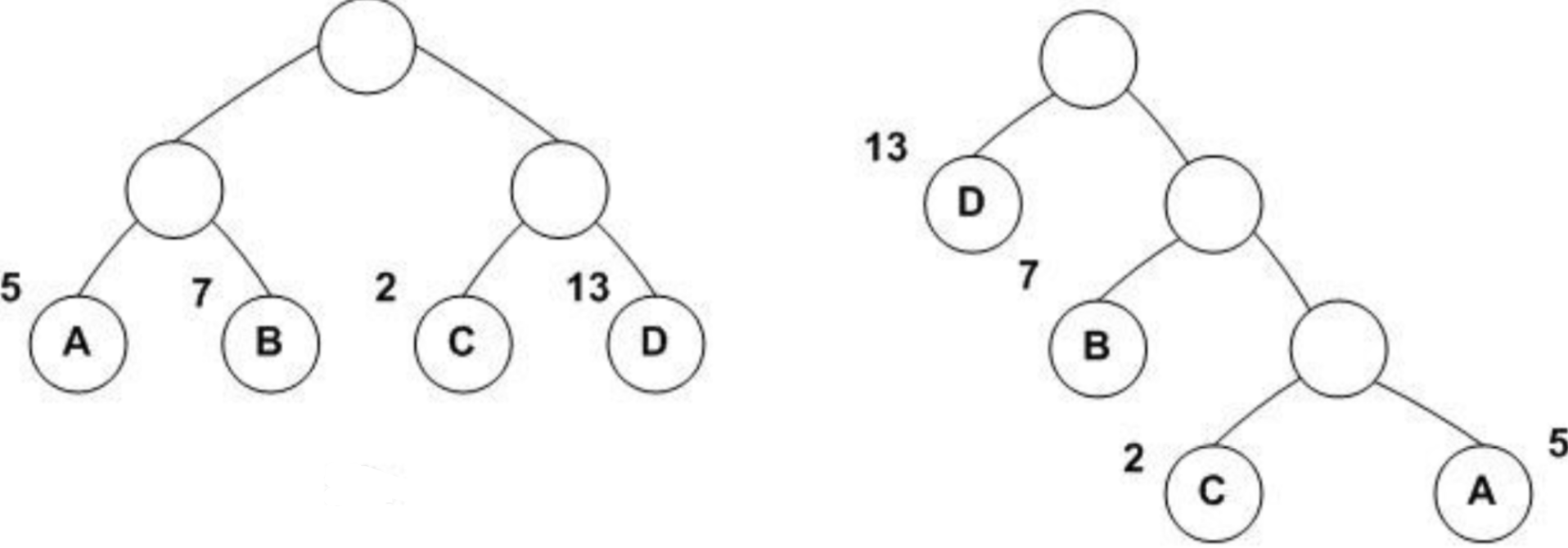
这里我们分别将叶子结点ABCD都赋予一个权值,我们来尝试计算一下,计算公式如下:
$$WPL = \sum_{i=1}^{n} \big( value(i) \times depth(i) \big) $$
那么左右两边的计算结果为:
-
左图: $WPL=5×2+7×2+2×2+13×2=54$
-
右图: $WPL=5×3+2×3+7×2+13×1=48$
通过计算结果可知,右图的带权路径长度最小,实际上右图是一棵哈夫曼树。
那么现在给了我们这些带权的叶子结点,我们怎么去构建一颗哈夫曼树呢?首先我们可以将这些结点视为4棵树,他们共同构成了一片森林:

首先我们选择两棵权值最小的树作为一颗新的树的左右子树,左右顺序不重要(因为哈夫曼编码不唯一,后面会说),得到的树根结点权值为这两个结点之和:
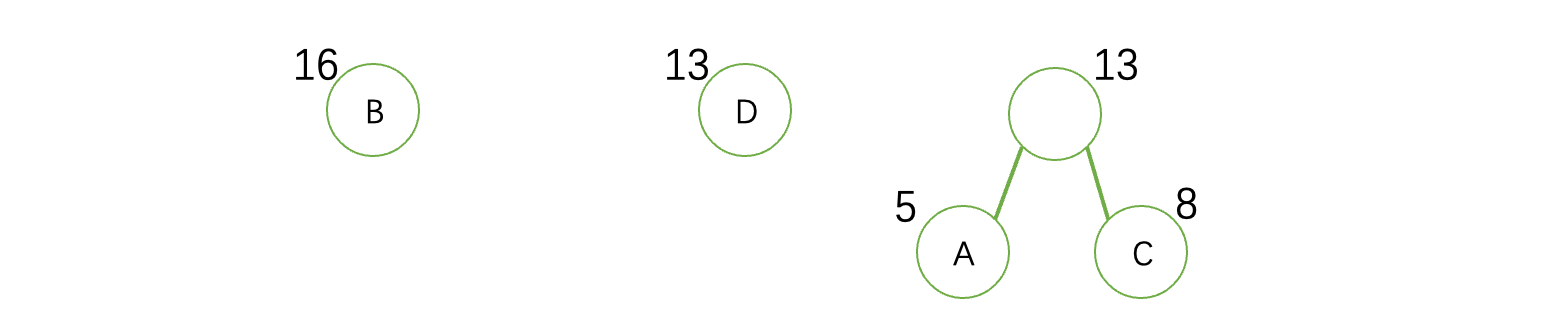
接着,我们需要将这这棵树放回到森林中,重复上面的操作,继续选择两个最小的出来组成一颗新的树,此时得到:
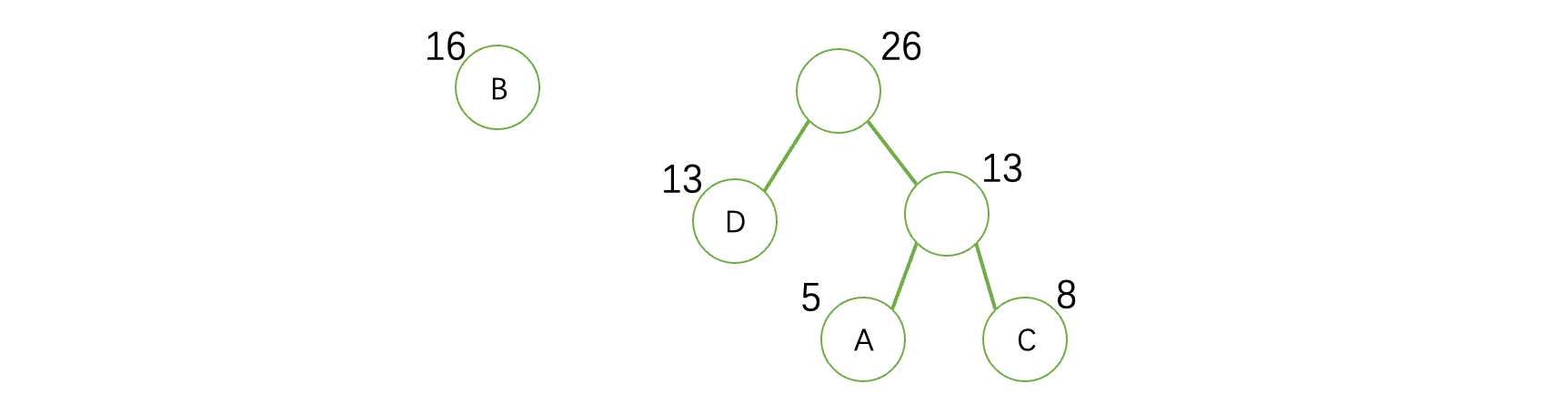
继续重复上述操作,直到森林里面只剩下一棵树为止:
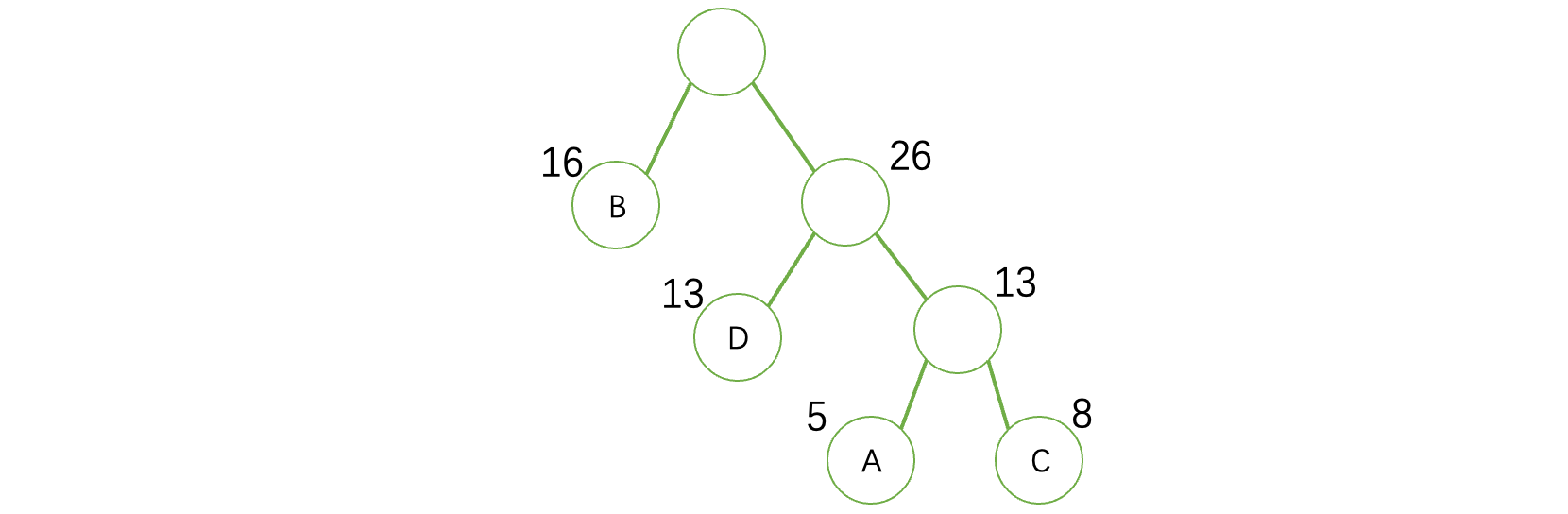
这样,我们就得到了一棵哈夫曼树,因为只要保证越大的值越靠近根结点,那么出来的一定是哈夫曼树。
我们辛辛苦苦把这棵树构造出来干嘛呢?实际上哈夫曼树的一个比较重要应用就是对数据进行压缩,它是现代压缩算法的基础,我们常常可以看到网上很多文件都是以压缩包(.zip、.7z、.rar等格式)形式存在的,我们将文件压缩之后。
比如这一堆字符串:ABCABCD,现在我们想要将其进行压缩然后保存到硬盘上,此时就可以使用哈夫曼编码。那么怎么对这些数据进行压缩呢?这里我们就可以采用刚刚构建好的哈夫曼树,我们需要先对其进行标注:
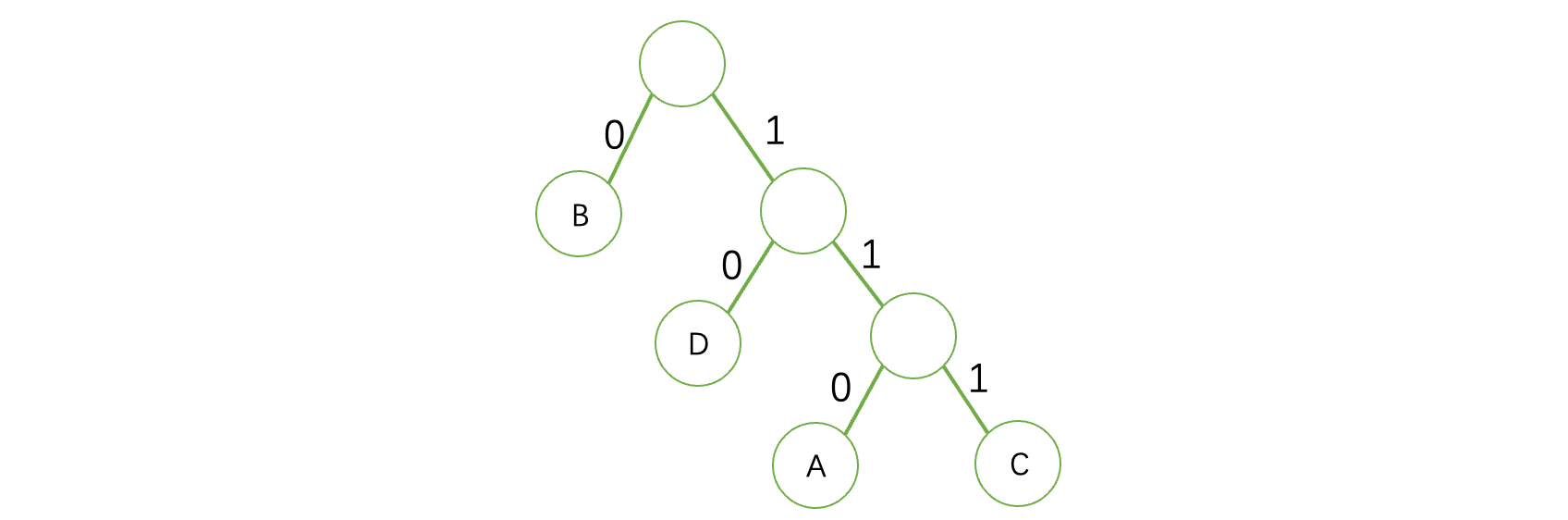
向左走是0,向右走是1,比如现在我们要求出A的哈夫曼编码,那么就是根结点到A整条路径上的值拼接: -
A:110
-
B:0
-
C:111
-
D:10
这些编码看起来就像二进制的一样,也便于我们计算机的数据传输和保存,现在我们要对上面的这个字符串进行压缩,那么只需要将其中的每一个字符翻译为对应编码就行了: -
ABCABCD = 110 0 111 110 0 111 10
这样我们就得到了一堆压缩之后的数据了。那怎么解码回去呢,也很简单,只需要对照着写回去就行了:
- 110 0 111 110 0 111 10 = ABCABCD
代码实现
我们来尝试编写一下代码实现一下哈夫曼树的构建和哈夫曼编码的获取把,因为构建哈夫曼树需要选取最小的两个结点,这里需要使用到优先级队列。
什么是优先级队列
优先级队列与普通队列不同,它允许VIP插队(权值越大的元素优先排到前面去),当然出队还是一律从队首出来。


这就是优先级队列,VIP插队机制,要实现这样的优先级队列,我们只需要修改一下入队操作即可:
1 | _Bool initQueue(LinkedQueue queue){ |
构建哈夫曼树
这样我们就编写好了一个优先级队列,然后就可以开始准备构建哈夫曼树了:
1 | typedef char E; |
首先按照我们前面的例子,构建出这四个带权值的结点:
1 | Node createNode(E element, int value){ //创建一个结点 |
1 | _Bool offerQueue(LinkedQueue queue, T element){ |
已经是按照权重顺序在排队了,接着我们就可以开始构建哈夫曼树了:
1 | int main(){ |
现在得到哈夫曼树之后,我们就可以对这些字符进行编码了,当然注意我们这里面只有ABCD这几种字符:
1 | char * encode(Node root, E e){ |
最后测试:
1 | int main(){ |
成功得到对应的编码:

可以看到结果就是优先级队列的出队结果,这样,我们就编写好了大顶堆的插入和删除操作了。
当然,堆在排序上也有着非常方便的地方,在后面的排序算法篇中,我们还会再次说起它。

说些什么吧!