
我们之前认识的查找算法,最快可以达到对数阶 $O(logN)二分$,那么我们能否追求极致,让查找性能突破到常数阶呢?这里就要介绍到我们的散列(也可以叫哈希 Hash)它采用直接寻址的方式,在理想情况下,查找的时间复杂度可以达到常数阶 $O(1)$。
散列表也就是哈希表有什么用
散列(Hashing)通过散列函数(哈希函数)将要参与检索的数据与散列值(哈希值)关联起来,生成一种便于搜索的数据结构,我们称其为散列表(哈希表),也就是说,现在我们需要将一堆数据保存起来,这些数据会通过哈希函数进行计算,得到与其对应的哈希值,当我们下次需要查找这些数据时,只需要再次计算哈希值就能快速找到对应的元素了:
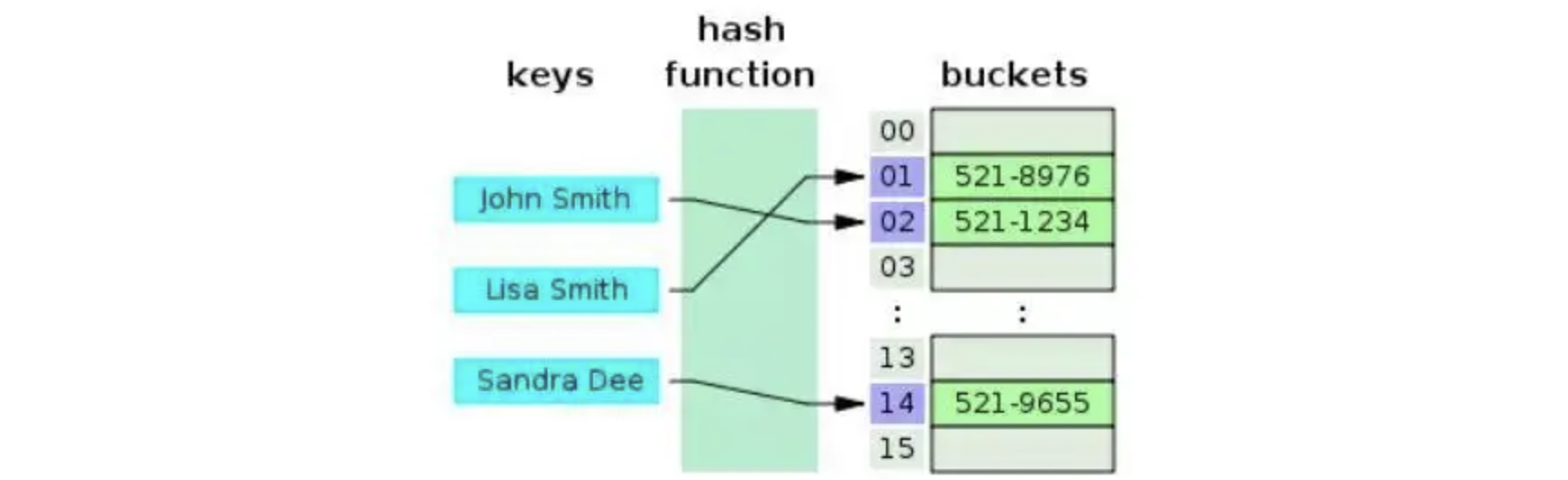
一脸懵逼没关系,我们从哈希函数开始慢慢介绍。
散列函数
散列函数也叫哈希函数,哈希函数可以对一个目标计算出其对应的哈希值,并且,只要是同一个目标,无论计算多少次,得到的哈希值都是一样的结果,不同的目标计算出的结果介乎都不同。哈希函数在现实生活中应用十分广泛,比如很多下载网站都提供下载文件的MD5码校验,可以用来判别文件是否完整,哈希函数多种多样,目前应用最为广泛的是SHA-1和MD5,比如我们在下载IDEA之后,会看到有一个验证文件SHA-256校验和的选项,我们可以点进去看看:
点进去之后,得到:
1 | e54a026da11d05d9bb0172f4ef936ba2366f985b5424e7eecf9e9341804d65bf *ideaIU-2022.2.1.dmg |
这一串由数字和小写字母随意组合的一个字符串,就是安装包文件通过哈希算法计算得到的结果,那么这个东西有什么用呢?我们的网络可能有时候会出现卡顿的情况,导致我们下载的文件可能会出现不完整的情况,因为哈希函数对同一个文件计算得到的结果是一样的,我们可以在本地使用同样的哈希函数去计算下载文件的哈希值,如果与官方一致,那么就说明是同一个文件,如果不一致,那么说明文件在传输过程中出现了损坏。
可见,哈希函数在这些地方就显得非常实用,在我们的生活中起了很大的作用,它也可以用于布隆过滤器和负载均衡等场景,这里不多做介绍了。
散列表
前面我们介绍了散列函数,我们知道可以通过散列函数计算一个目标的哈希值,那么这个哈希值计算出来有什么用呢,对我们的程序设计有什么意义呢?我们可以利用哈希值的特性,设计一张全新的表结构,这种表结构是专为哈希设立的,我们称其为哈希表(散列表)

我们可以将这些元素保存到哈希表中,而保存的位置则与其对应的哈希值有关,哈希值是通过哈希函数计算得到的,我们只需要将对应元素的关键字(一般是整数)提供给哈希函数就可以进行计算了,一般比较简单的哈希函数就是取模操作,哈希表长度是多少(长度最好是一个素数),模就是多少:

比如现在我们需要插入一个新的元素(关键字为17)到哈希表中:
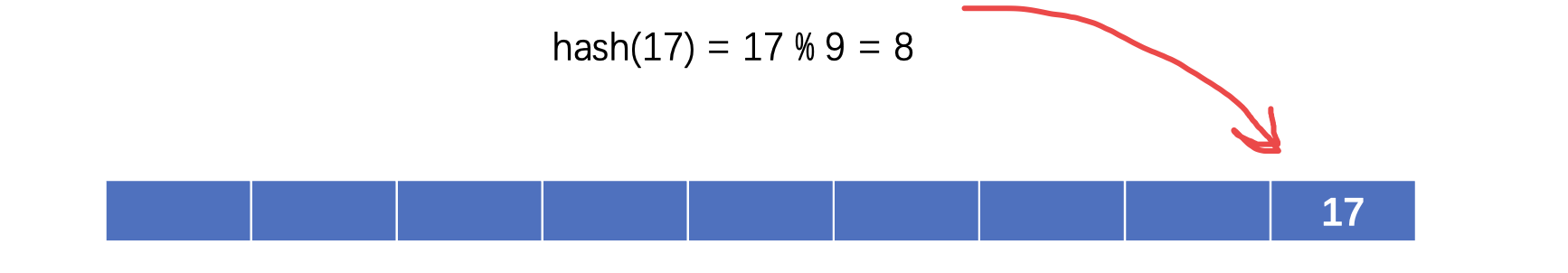
插入的位置为计算出来的哈希值,比如上面是8,那么就在下标位置8插入元素,同样的,我们继续插入27:
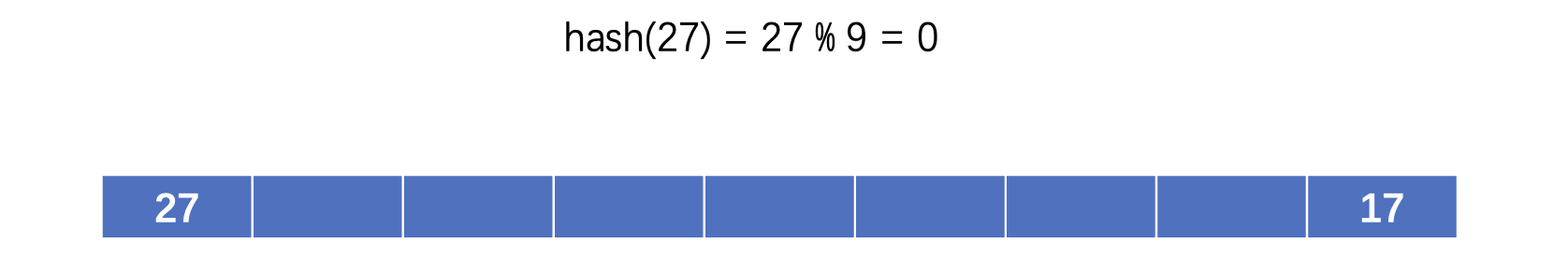
这样,我们就可以将多种多样的数据保存到哈希表中了,注意保存的数据是无序的,因为我们也不清楚计算完哈希值最后会放到哪个位置。那么如果现在我们想要从哈希表中查找数据呢?比如我们现在需要查找哈希表中是否有14这个元素:

同样的,直接去看哈希值对应位置上看看有没有这个元素,如果没有,那么就说明哈希表中没有这个元素。可以看到,哈希表在查找时只需要进行一次哈希函数计算就能直接找到对应元素的存储位置,效率极高。
我们可以通过代码来实现一下:
1 |
|
这样,我们就实现了一个简单的哈希表和哈希函数,通过哈希表,我们可以将数据的查找时间复杂度提升到常数阶。

说些什么吧!