
什么是哈希冲突
前面我介绍了哈希函数,通过哈希函数计算得到一个目标的哈希值,但是在某些情况下,哈希值可能会出现相同的情况:

这种情况,我们称为哈希碰撞(哈希冲突)
这种情况是不可避免的,我们只能通过使用更加高级的哈希函数来尽可能避免这种情况,但是无法完全避免。当然,如果要完全解决这种问题,我们还需要去寻找更好的方法。
线性探测法
我们可以选择退让,不去进行争抢,我们可以去找找哈希表中相邻的位置上有没有为空的,只要哈希表没装满,那么我们肯定是可以找到位置装下这个元素的,这种类型的解决方案我们统称为线性探测法
既然第一次发生了哈希冲突,那么我们就继续去找下一个空位:
$$h_i(\text{key}) = \left(h(\text{key}) + d_i\right) \% \text{TableSize} $$
其中 $d_i$ 是随着哈希冲突次数增加随之增加的量,比如上面出现了一次哈希冲突,那么我就将其变成1表示发生了一次哈希冲突,然后我们可以继续去寻找下一个位置:
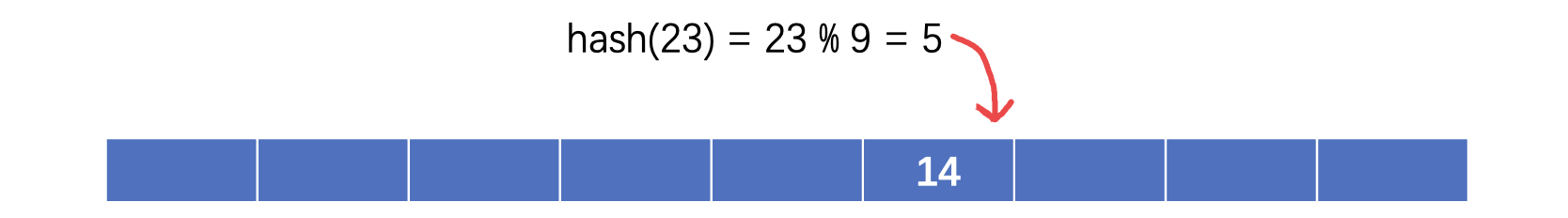
出现哈希冲突时,didi自增,继续寻找下一个空位:
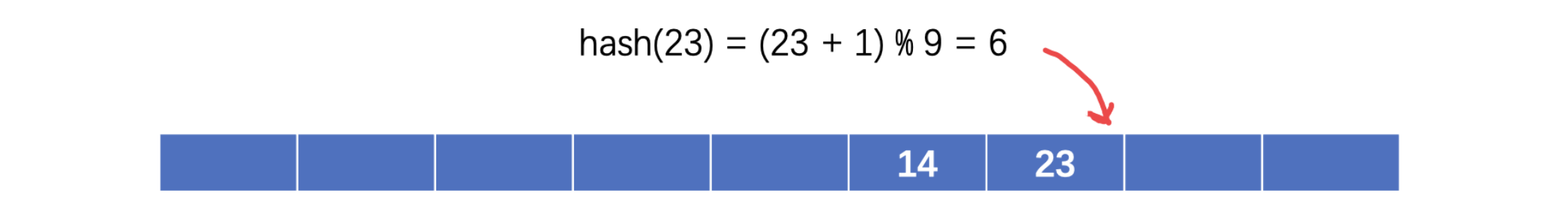
再次计算哈希值,成功得到对应的位置,注意 didi 默认为0,这样我们就可以解决冲突的情况了。
插入和查找操作
1 | void insert(HashTable hashTable, E element){ //插入操作,注意没考虑满的情况,各位小伙伴可以自己实现一下 |
这样当出现哈希冲突时,会自动寻找补位插入:
1 | int main() { |
连地址法
实际上常见的哈希冲突解决方案是链地址法,当出现哈希冲突时,我们依然将其保存在对应的位置上,我们可以将其连接为一个链表的形式:
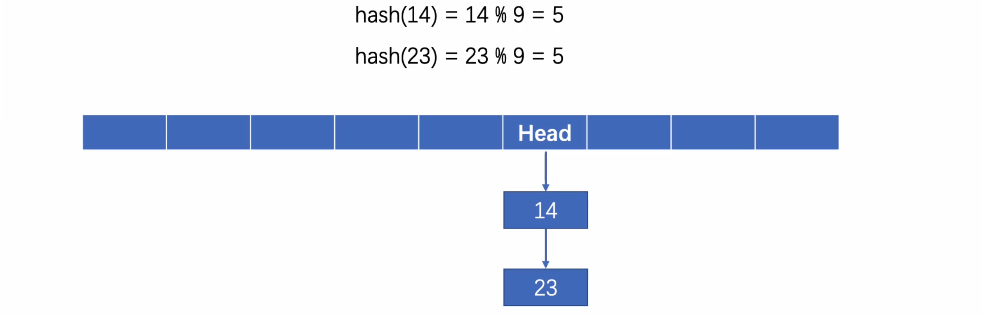
当表中元素变多时,差不多就变成了这样,我们一般将其横过来看:
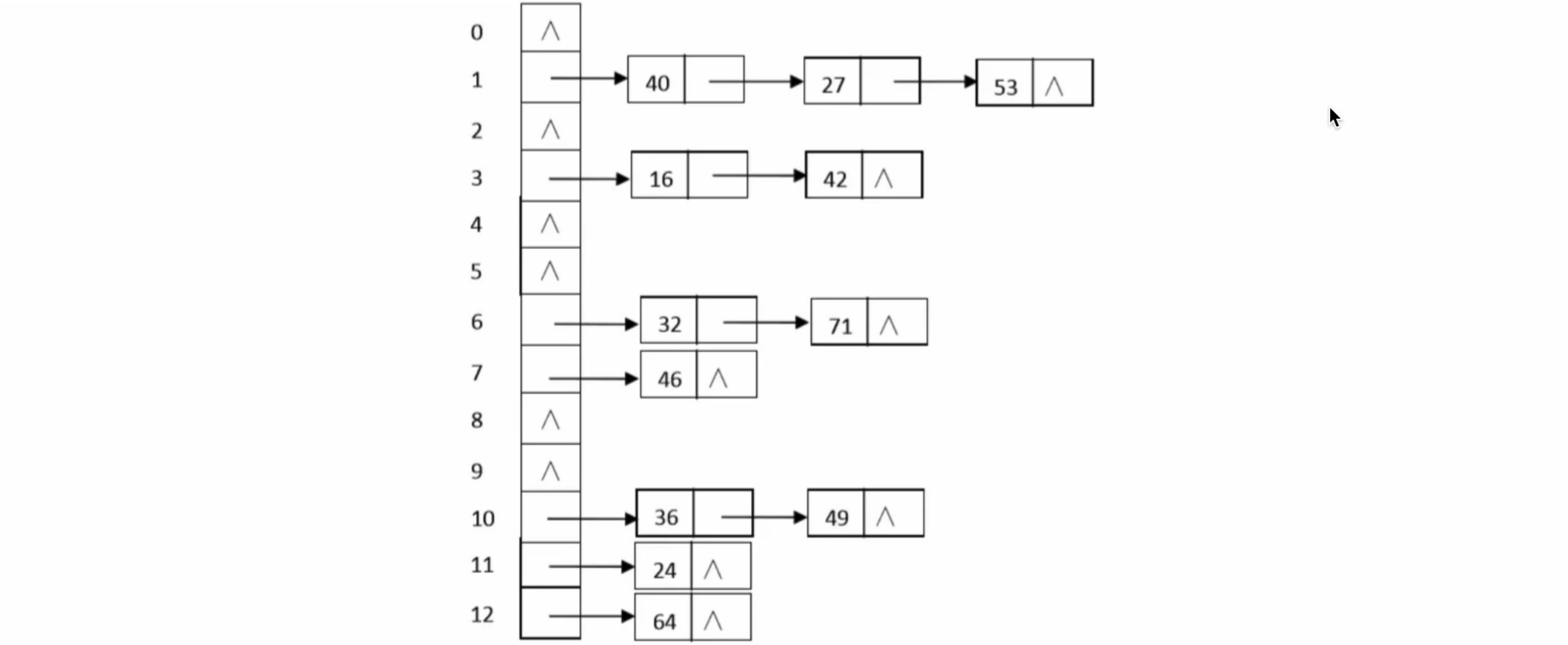
通过结合链表的形式,哈希冲突问题就可以得到解决了。但是同时也会出现一定的查找开销,因为现在有了链表,我们得挨个往后看才能找到,当链表变得很长时,查找效率也会变低,此时我们可以考虑结合其他的数据结构来提升效率。
比如当链表长度达到8时,自动转换为一棵平衡二叉树或是红黑树,这样就可以在一定程度上缓解查找的压力了。
我们来编写代码尝试一下:
1 |
|
插入操作
接着是编写对应的插入操作,插入后直接往链表后面丢就完事了:
1 | int hash(int key){ //哈希函数 |
查找操作
同样的,查找的话也是直接找到对应位置,看看链表里面有没有就行:
1 | _Bool find(HashTable hashTable, int key){ |
接着我们可以通过下方代码测试:
1 | int main(){ |
实际上这种方案代码写起来也会更简单,使用也更方便一些。

说些什么吧!