
首先给个爸爸像儿子的爆论,经过学习Python基础后,Python简直就是Gds
开端
python解释器
在第一次写下python代码之前,我们需要了解到python是通过解释器来解释成计算机语言的,这与某些语言的编译器有些许差别,所以我们需要下载python解释器来执行。
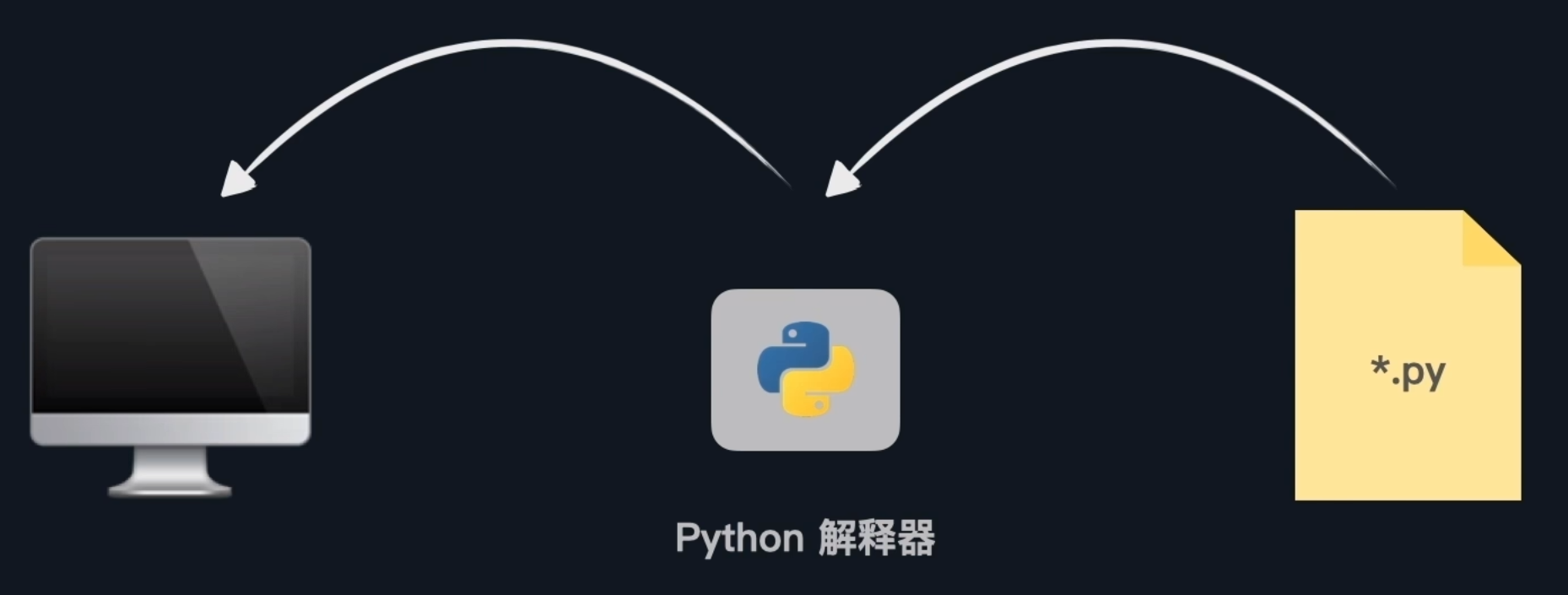
而python的运行过程是翻译一行,执行一行
我们一般说安装python,本质就是安装python解释器
python代码编辑器
我们这边使用的是PyCharm编辑器,当我们创建好项目后,需要熟悉以下东西
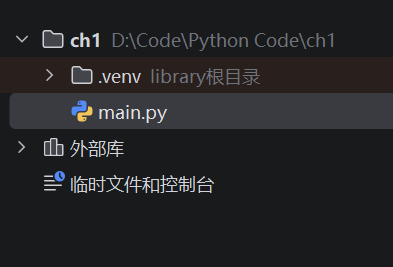
venv表示这个项目独立的Python虚拟环境,可以让不同项目可以用不同的解释器版本,还有安装第三方库等等,这个文件夹别动它就行,也别往里面加东西外部库就是自己添加库ch1下创建python文件
python特性
tab缩进
在python中我们的代码并不是用;来分割的,而是直接跳转到下一行。并且在如if和while语句中,我们不会使用{}来区分代码块,而是靠tab缩进来进行,比如以下代码:
1 | print ("hello") |
记得语句开头不要用空格
print打印
在python中我们打印只需要一行代码
1 | print ("qwq") |
\转义符
这里用'和"都行,如果我们想要在""或者’'中打印引号,我们可以使用\"来解决,比如以下代码
1 | print ("He said \"Let\'s go!\"") |
\n换行符
1 | print ("Hello! \nHi!") |
输出结果
1 | Hello! |
我们要注意的是,一个print语句自带换行效果。
“”"换行符
如果我们的内容非常多需要多次换行怎么办?多个\n显然不太合适,多行print有点费劲,那么我们可以采用连续三个‘’‘或者"""来括住语句,它会自动根据字符串换行而换行
1 | print("""A |
输出结果
1 | A |
变量
在学习python的变量前,我们要先注意一件事,那就是python变量名不能用数字打头,不能有下划线以外的符号
这🐂魔语言甚至可以不用声明变量类型,fku
1 | a = 1; |
执行结果
1 | 1 |
在命名规则方面我们还要注意,是可以有中文的,接着要注意以下几点
- 变量名是大小写敏感的,
user_age != User_age - 不要占用关键字
- 最好是下划线命名法
在python中我们如果一个变量为空,用的并不是C中会使用的NULL,而是None
数学运算
平方符号
在python中如果我们想表示一个数的几次方,就用**来表示,比如下列代码
1 | a = 2 ** 3; |
运行结果
1 | 8 |
math函数库
1 | import math #导入函数库 |
我们可以去官方的math库文档来查看支持那些函数运算
math — 数学函数 — Python 3.14.3 文档
'#'注释
比如我们上方这里的#导入函数库,就是注释。
在PyCharm中,我们如果想要多行代码注释,我们可以使用快捷键
- Win系统:control + /
- masOS:command+/
其实我们也可以用三引号来进行多行注释,但是我们刚才学过了,这个东西不是在输出中进行换行的吗?确实是这样,但如果我们把一堆代码头尾用三引号来括住,那不就是告诉我们这一大段就是字符串吗,自然就被注释掉了
type函数
type()函数可以返回你的定义变量的数据类型
1 | a = 1 |
运行结果
1 | <class 'int'> |
input输入函数
1 | #input函数名后面加括号,里面的信息为提示给用户的信息 |
只要有这一行,就会开始等待用户输入
input默认会让用户输入的任何数据为字符串,哪怕你输入的是1,a也不能参与数学运算,那么该怎么办?我们可以这样
1 | user_age = int(input("您的真实年龄")) |
if条件语句
在python当中我们的if语句不用加括号
1 | a = false |
与非或的逻辑运算
- and:与
- or:或
- not:非
1 | x = 1 |
运行结果
1 | True |
[]列表
本质为可以容纳万物的顺序表
1 | shopping_list = ["键盘","键帽"] #声明 |
运行结果
1 | ['你好', 1, True] |
还有很多针对链表的内置函数,拿纯数列表举例
- max:列表中的最大值
- min:列表中的最小值
- sorted:排序好的列表
{}字典
和现实当中的字典很相似,我们可以通过键key来查找`值value’
键 :值,如下图
1 | ID = {"小明":"137000000", |
tuple元组
需要注意的是,键的类型必须是不可变的,而列表属于可变值类型,列表不能作为键,感觉少了点功能,但是说不上来…怎么办呢?python很贴心的为我们准备了一个新的数据结构,元组tuple
1 | example_tuple = ("键盘","键帽") #元组用圆括号 |
另外由于元组不可变,所以添加删除操作都不可用,但是终于实现了以下代码:
1 | ID = {("小明", 20): "1500001", |
字典的操作
字典同样也具有添加,删除,更新操作:
1 | ID = {"小明": "1500001", |
for循环
for循环在Python中遵循以下遍历原则
1 | for 变量名 in 可迭代对象: |
可迭代对象就是列表或者字符串之类的,然后按顺序从左至右一个一个返回给变量名。
接着还要了解如何迭代字典:
1 | ID = {"小明": "1500001", |
range范围取值
1 | range(5,10) #其实就是5-9范围内,10并不会包含进去 |
while循环
while和其他语言的while没啥区别,但还是写个例子吧
1 | i = 0 |
格式化字符串
我们在修改字符串中的某些东西输出时,可能会用+来进行字符串拼接,但是有一说一挺丑的,不信可以自己写个试试。于是python为我们提供了以下方法
format 方法
1 | year = 1000 |
运行结果:
1 |
|
f字符串
1 | year = 1000 |
运行结果
1 |
|
保留有效数字
并且我还可以,以format为例
1 | year = 1000 |
运行结果
1 |
|
def函数
软件开发里面有个DRY原则,Don’t Repeat Yourself ,不要做代码复读机
我们用def来声明函数,不必像java或者C一样需要用特定的数据类型来定义函数,如果没有return语句就是返回None,否则就会自动判定return的变量类型,然后进行返回。
我们以计算扇形面积为例
1 | def calculate_sector_1(central_angle, radius): |
import引入模块-使用他人早就写好的东西
python虽然已经为我们准备好了如sum()这类早就写好的自带函数,我们同样可以使用import来引入其他模块,来使用这些模块里面所带的函数
引入模块的方式有3种
- import
模块名语句:使用模块名.函数名/变量名来使用 - from
模块名import函数名/变量名, 函数名/变量名语句:使用函数名/变量名来使用 - from
模块名import*语句:会将模块的东西全部引入,使用函数名/变量名来使用
关于第三方库的模块如图所示:
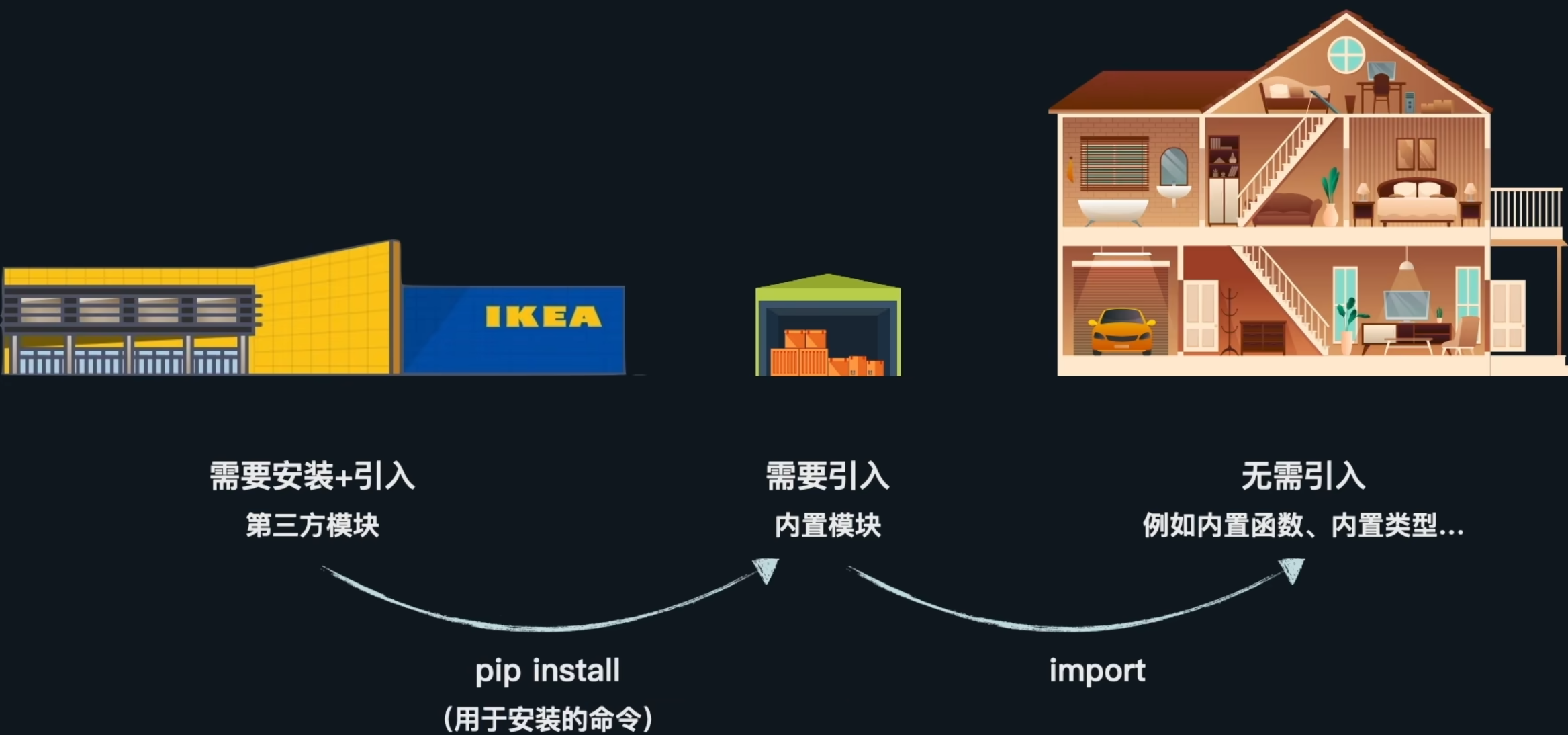
我们可以通过这个网站来搜索第三方库:点我进入
面向对象编程
创建类
首先说下命名规则,Python在创建类的时候最好首字母大写,语法如下
1 | class CuteCat: |
接着我们要了解构造函数_init_这个函数,即为构造方法,本身就写好的
而对象自身就是self
接着我们要来进行属性定义:
1 | class CuteCat: |
运行结果:
1 | jojo |
创建方法
我们还是用上面的猫猫一样来举例
1 | class CuteCat: |
类继承
就类似于java的子类父类之间继承,我只需要学会python的语法就好
1 | class Mammal: |
文件操作
文件路径
文件路径分为相对路径和绝对路径
- 相对路径:相对于此时运行代码的文件在哪里的文件,及从本文件目录开始出发
- 绝对路径:相当于整个计算机
放几张图自己品吧
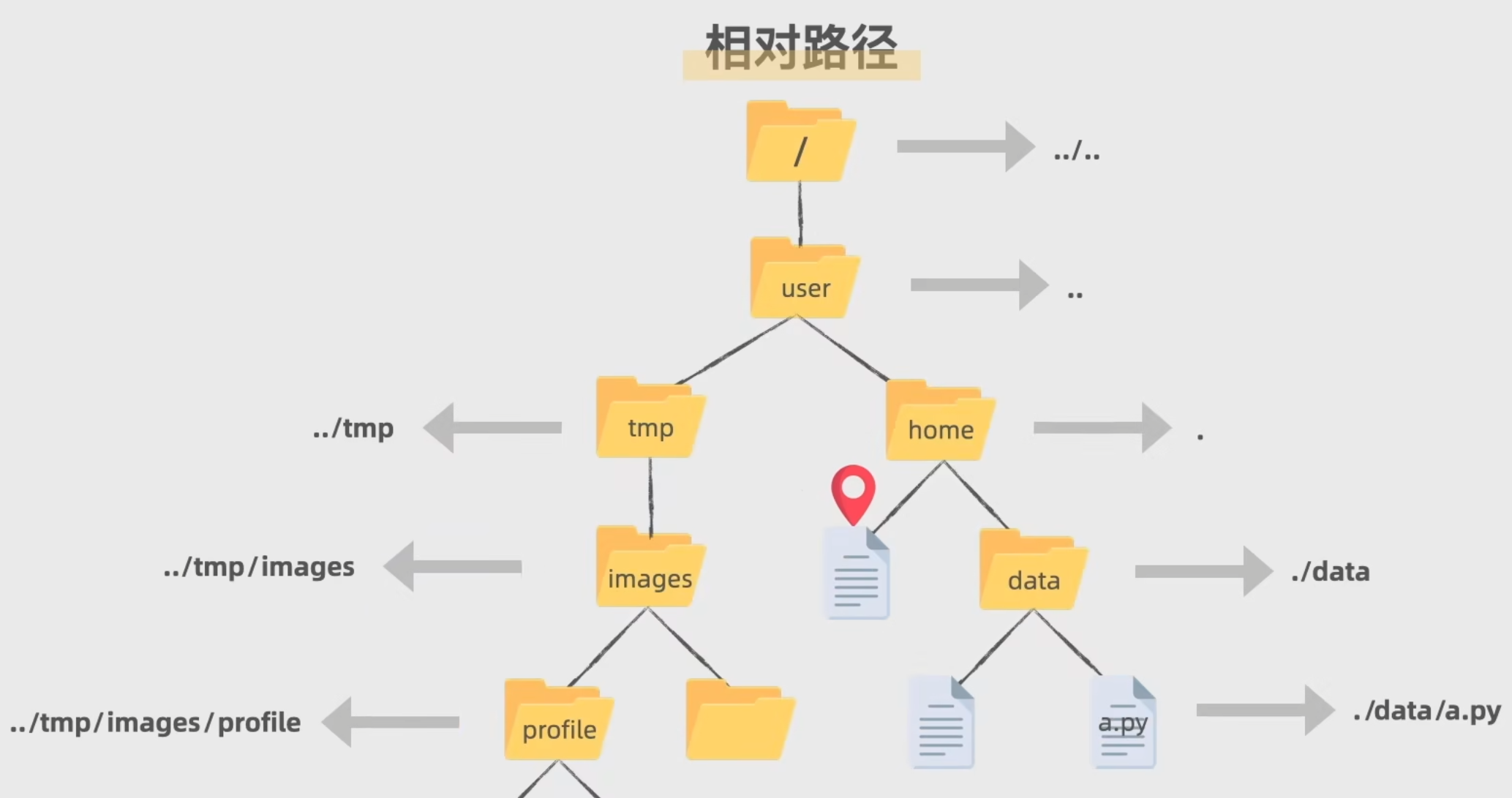
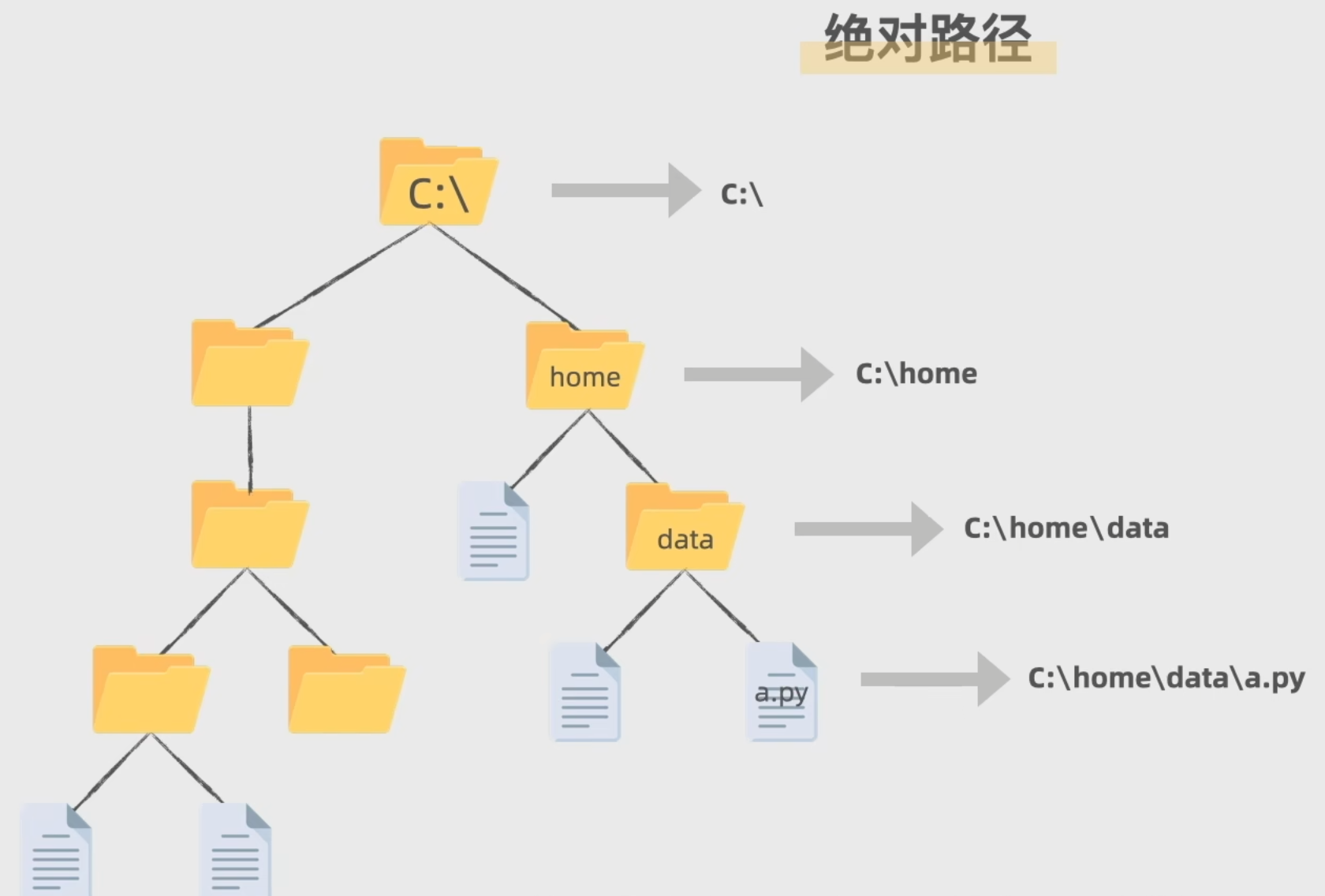
另外./是可以省略的
读取文件
用python读取文件的关键就是得先打开关键,这里我们会使用open("路径", 模式 ,(可选)encoding = "utf-8")函数来打开,通用模式分为以下四种
- “r” :读取模式(只读)
- “w”:写入模式(只写)
- “a”:写入追加
- “r+”:读+追加
当然这个参数可以不写,不写自动为读取。在读取模式下,如果找不到该文件的话,就会报出FileNotFoundError错误。
如果open函数返回成功,那么将会返回一个文件对象,我们可以后期对它进行读取或写入操作
1 | f = open("./data.text","r",encoding="utf-8") #f为文件对象 |
另外我们会发现以下问题
1 | f = open("./data.text","r",encoding="utf-8") #f为文件对象 |
为什么会为空呢?是因为程序会记录这个文件读取到哪个位置了,第一次read已经读到了结尾,就导致第二次read没有内容了。
另外如果文件特别大的话千万不要用read读取整个文件,要不然可能会直接爆了,我们可以给read传递一个数字,表示读多少个字节,下次调用read的时候就会从这个字节继续往下读:
1 | f = open("./data.text","r",encoding="utf-8") #f为文件对象 |
除了read,我们也可以用readline方法来读取文件,这个文件只会读取一行的内容,下次调用就读下一行。它会根据换行符来判断什么时候为本行结尾,而且换行符也会被当成读到的内容的一部分。那么我现在有一个问题,假如文件有无数行,我怎么知道要调用多少次才能读到结尾呢?
1 | f = open("./data.text","r",encoding="utf-8") #f为文件对象 |
当然一行一行读也是有点麻烦的,那么还有还有还有一个方法叫readlines,比之前的多了一个s。readlines会读取每行每行的内容,并且把它们组成一个字符串列表:
1 | f = open("./data.text","r",encoding="utf-8") #f为文件对象 |
现在我们已经学会了三种方法,来总结下吧
- read:返回全部文件内容的字符串
- readline:返回一行文件内容的字符串
- readlines:返回全部文件内容组成的列表
当然在读取所有文件后记得关闭文件,释放资源,文件对象有一个叫做close的方法,调用后就会释放资源:
1 | f = open("./data.txt") |
那么如果我们害怕忘记close该怎么办呢,我们可以使用with…as…方法来缩进成一个代码块,在这个代码块运行到最后将会自动close:
1 | with open ("./data.txt") as f: |
写入操作
与读取文件不同,如果写文件的话,根据路径找不到文件,并不会报错,而是会创建一个同名文件。另外要注意的是,如果用w模式开启写入的话,如果那个文件本身存在,那么将会把里面清空。 所以用w模式前要三思而后行。
1 | with open("./data.txt", "w", encoding = "UTF-8") as f: |
文件里面将会变成这样:
1 | Hello!Yoooo |
所以write并不会在每次写入都帮你换行,你还需要手动加换行符
1 | f.write("Hello!\n") |
那么如果我不像把原本文件清空的话,只想在后面追加内容,那么就不能用w作为模式,而是用a来表示附加内容:
1 | with open("./data.txt", "a", encoding = "UTF-8") as f: |
另外在w和a的模式下,如果我们想强制进行read操作是不被允许的,但是有一种方法可以
1 | with open("./data.txt", "r+", encoding = "UTF-8") as f: |
并且这里的write是以追加形式
try/except捕捉异常
在写代码过程中我们勉为其难的会发生一些错误,而这些错误将会以如FileNotFoundError这类爆出来提醒我们。并且代码运行到这里将会直接停止,这在我们日常运行当中明显不是我们想要的。所以我们需要学会在程序炸之前走一波预算,来捕捉这个异常,然后用我们想要的方式来处理异常,我们可以使用try/except语句来捕捉异常
1 | try: |
我们要知道except语句在捕捉错误的时候是从上向下进行。
python的测试
除了上面的捕捉异常,我们有时候写完一个东西也得测试bug。
assert语句
assert后面可以跟上任何布尔表达式,测试时我们会在assert后面加上我们认为应该为True的表达式
- assert后面的表达式为True:无事发生
- assert后面的表达式为False:立刻爆出
AsserttionError断言错误
断言错误相当于提示正在运行错误的人这里不符合预期,但是assert也有一个问题,只要出现AsserttionError,程序将会直接中止了,后面如果有更多代码也不会运行,我们并不知道后面的代码里还有哪些其他问题,所以我们一般会使用专门做测试的库他们能一次跑多个案例,并且能直观的展示哪些通过了,哪些没有。
unittest单元测试库
单元测试的意思是对软件中最小可观测单元进行验证,比如验证某函数某方面表现是否符合预期。
这个是python自带库。
另外我们一般会把测试代码放在独立文件中,而不是和要测试的功能混在一起。
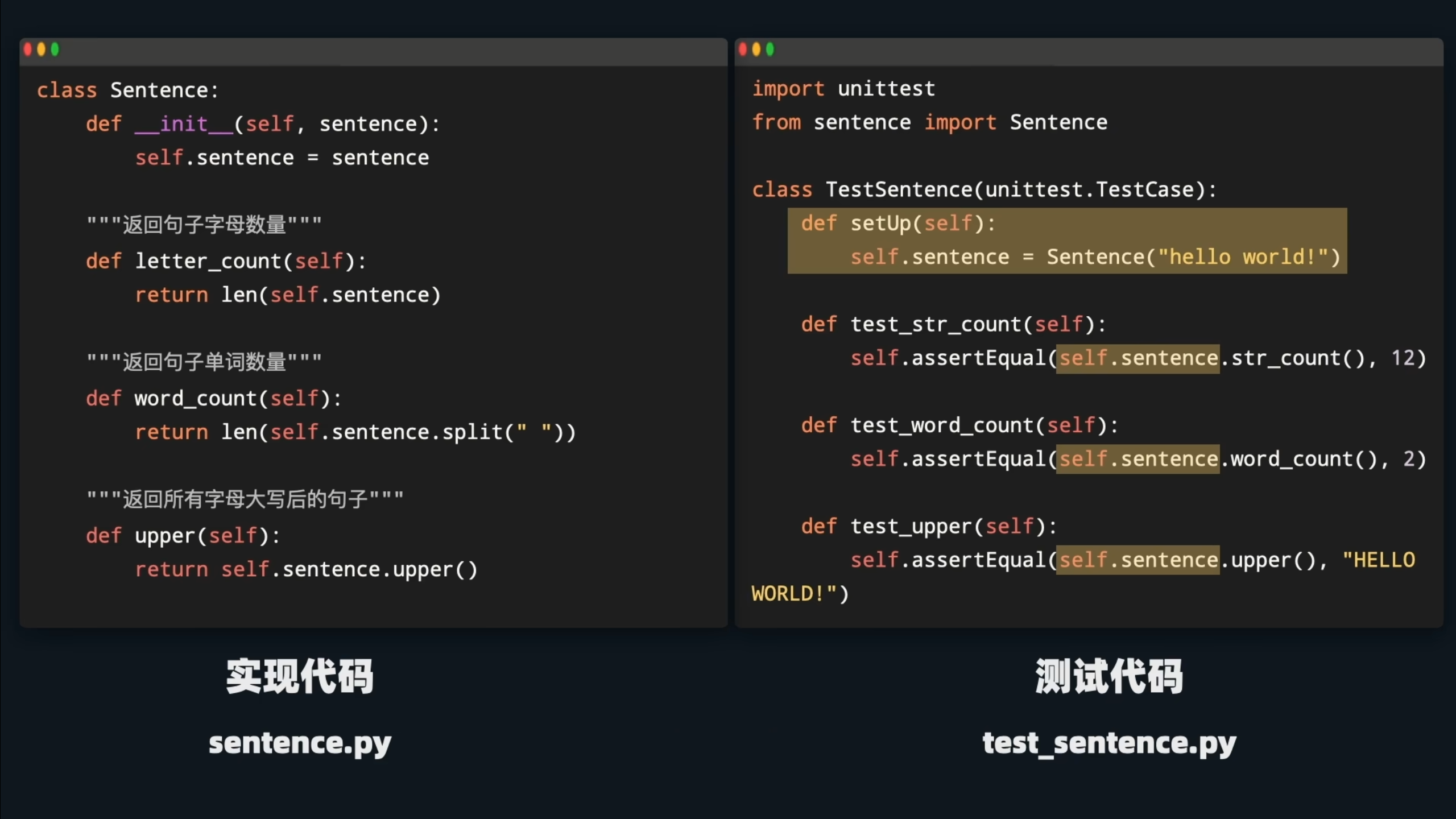
首先我们在同文件夹下创建一个测试文件:
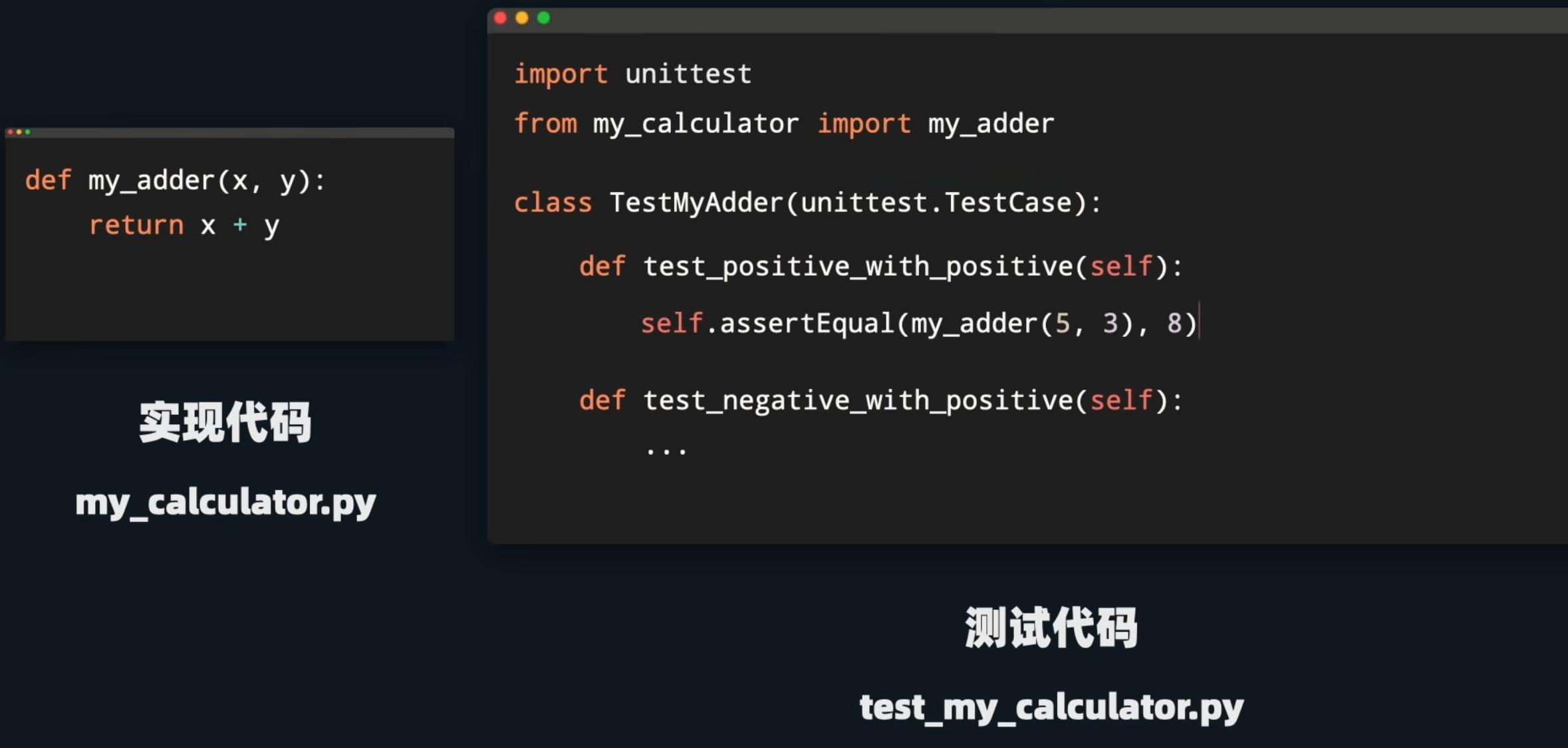
创建unittest库下TestCase类的子类,然后在其中写上 test_开头的测试代码,然后使用自身携带的assertEqual代码,将第一个和第二个比较。
这里的from…import则是从同文件夹下导入的函数或者类。
接着我们到达PyCharm测试文件的终端,输入以下命令python -m unittest表示运行unittest,这个就会运行所有继承了unittest库里TestCase类的子类,运行他们所有以test_开头的方法
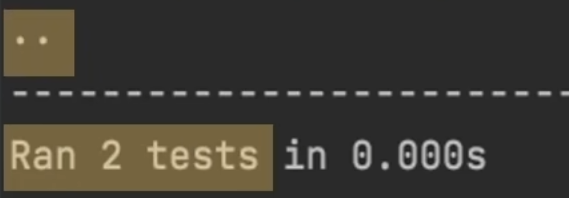
上面的··就是所有案例已通过。如果不通过的话,将会以下图呈现:
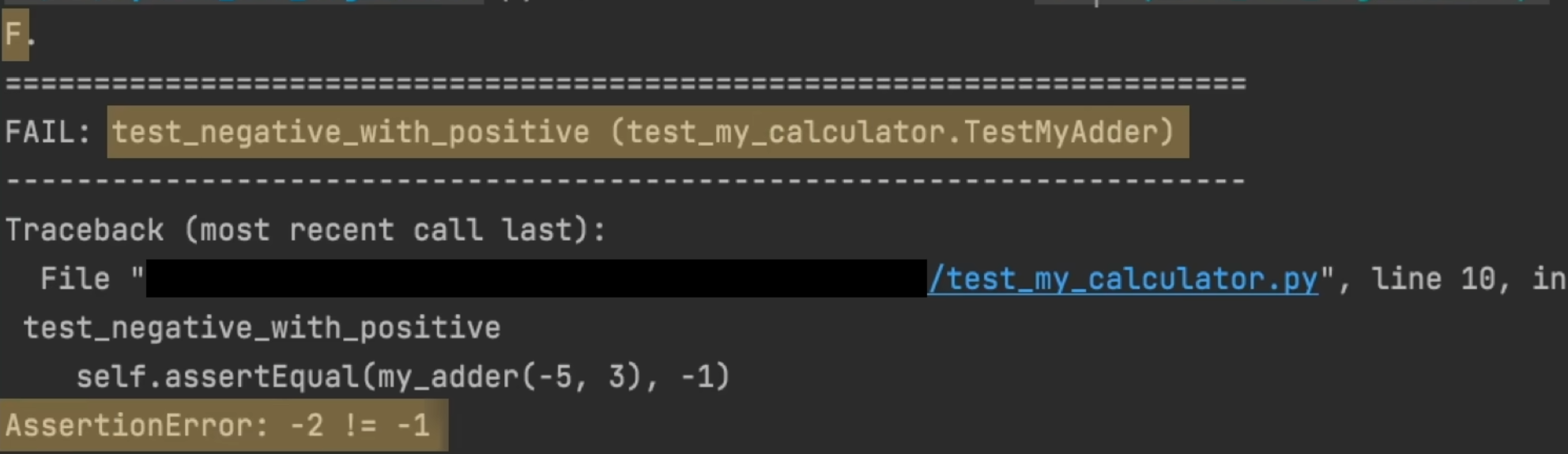 他会告诉你哪个失败了,以及为什么失败,一体化的体现了测试有关所有信息。
他会告诉你哪个失败了,以及为什么失败,一体化的体现了测试有关所有信息。
更多assert测试方法

setup方法
如果我们要测试某个类里面的方法,那么我们需要在每个test_语句下创建对象,很浪费空间和时间。所以我们可以用到setup方法,在每次运行test_方法前都会先运行一遍setup方法。
高阶函数
直接来看一个图就懂了
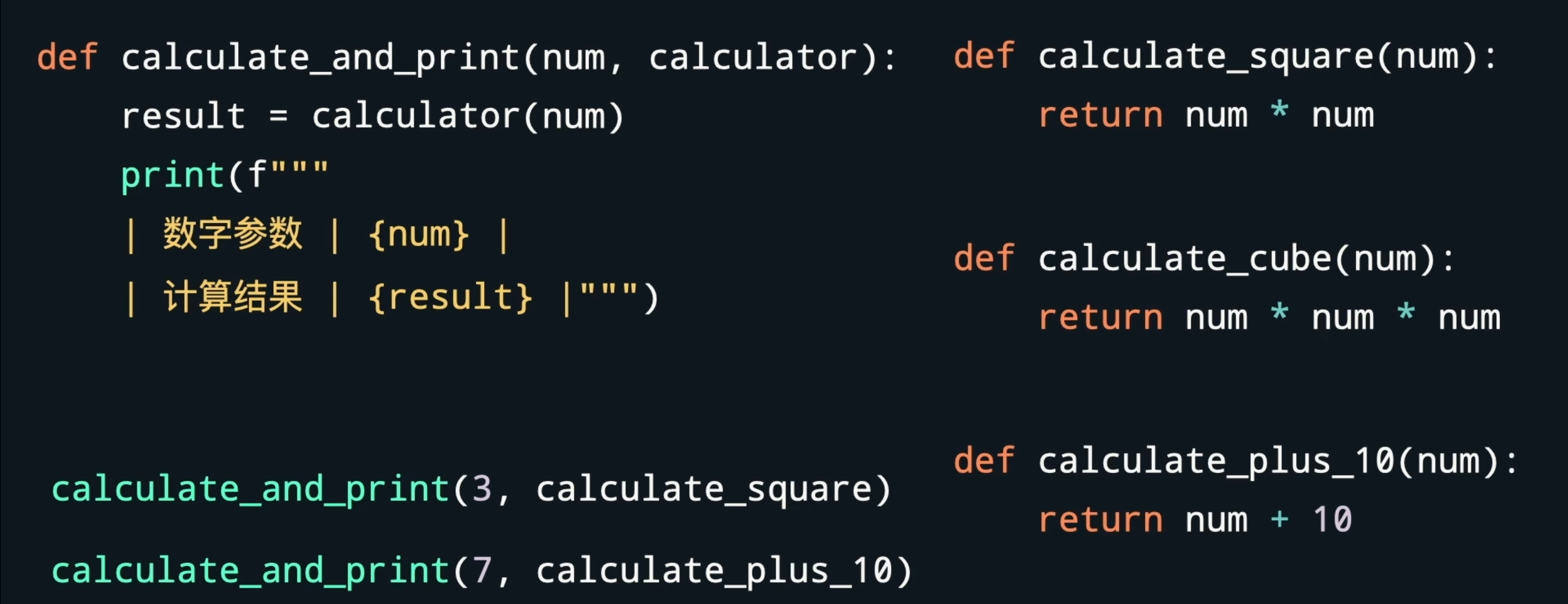
没错,函数是可以传入函数的。这种把函数当成参数的函数就被叫做 高阶函数
我们要注意的是,函数传入时不能带括号(),要不然就被调用了。而这些我们当作参数的函数,实际上我们一般是不会直接调用来使用的,所以它们也有酷炫的名字,叫做 匿名函数,又或者叫它$Lambda$
我们甚至可以这样
1 | def ji_suan(1,2,lambda num1,num2: num1 + num2): |
它也可以被定义好后直接调用:
1 | (lambda num1,num2: num1 + num2)(2,3) |
但是lambda函数的局限性就是只能冒号后只能有一个表达式

说些什么吧!