
什么是爬虫
爬虫爬的好,牢饭吃的早。但本身来讲数据是无罪的,爬虫作为一个便携且低成本获取数据的方式,现如今非常广泛,但还是要遵纪守法的,有些东西不该你知道就别动。
还要记住,爬虫的请求数量和频率不能过高,要不然和DDoS攻击没什么区别了。如果网站本身有反爬机制,那就别去强行突破了。
我们可以通过查看网站的robots.txt文件,了解可爬取的网页路径范围,这个文件会指明哪些网站会允许被爬取,哪些不允许被爬取。

爬虫的流程
爬虫的流程可能比你想象中的更简单
第一步:获取网页内容
我们会通过代码给一个网站服务器发送请求,它会返回给我们网页上的内容。
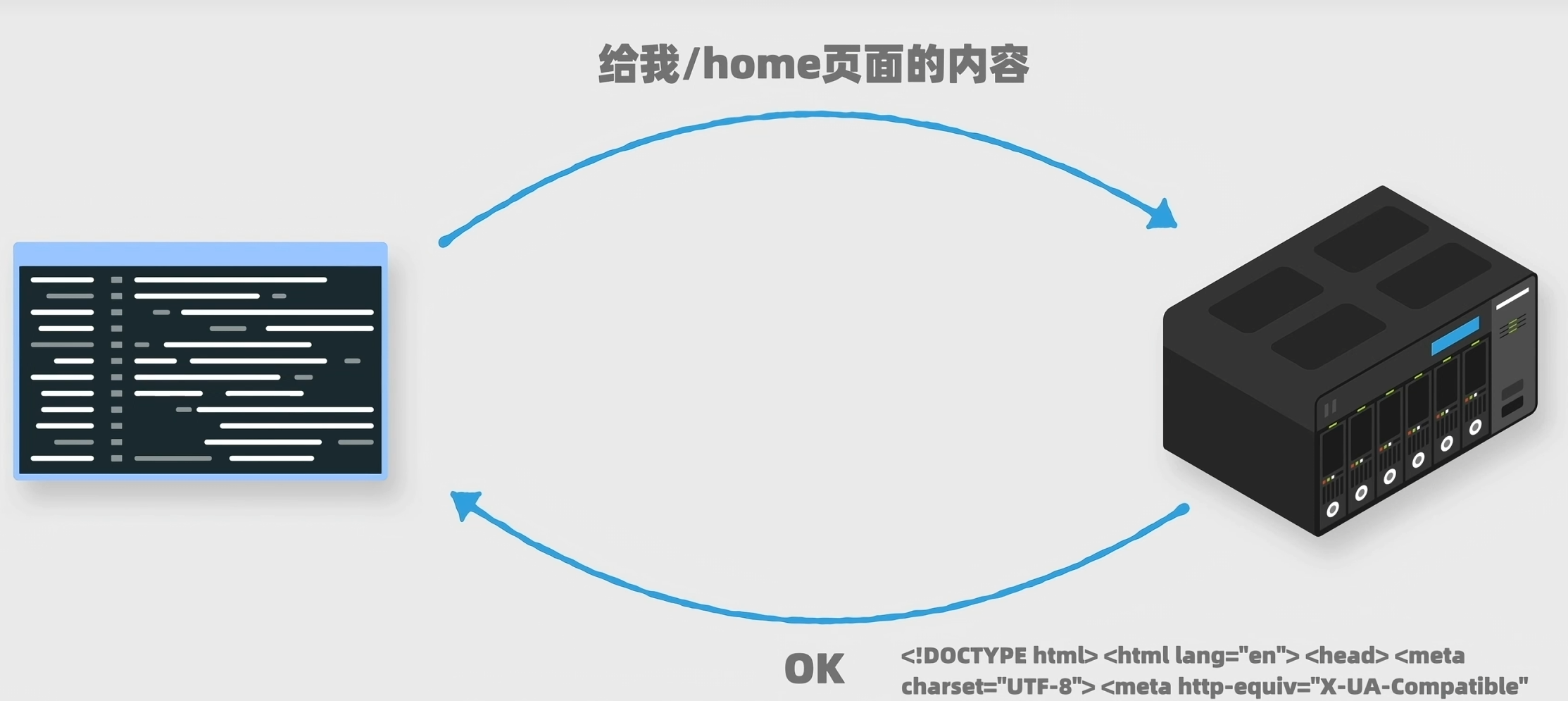
在我们平时使用浏览器访问网页内容时,本质上也是给网站服务器发送一个请求,服务器返回网页内容,只不过浏览器还会进行一个额外的步骤,就是把内容渲染成直观美观的页面。而用程序获得的内容,因为没有渲染步骤,所以我们看到的更加原始。
第二步:解析网页内容

我们在上一个步骤可以获取整个网页的内容,但那太多太全了,很可能不是我们想要的,所以需要把我们想要的内容提取出来。

第三步:储存或分析数据
这一步的如何执行就是看用户的具体需求了。
- 收集数据集:把数据储存进数据库
- 分析数据趋势:把数据做成可视化图表
- 舆论监控:用AI做文本情绪分析
总结
这些步骤适用于一个网页内容的情况,当然我们还可以给一串网址,让程序一个一个去爬取;或者让程序以某个网址为根,顺着把那个网页上链接指向的地址也爬取一遍。
HTTP请求和响应
我们将通过发送HTTP请求来获取网页内容。HTTP(Hypertext Transfer Protocol)意思是超文本传输协议。它是一种客户端和服务器之间请求-响应协议。我们可以把浏览器看成一个客户端,我们输入网址按下回车就会向服务器发送一个HTTP请求,然后等待服务器返回给浏览器响应。
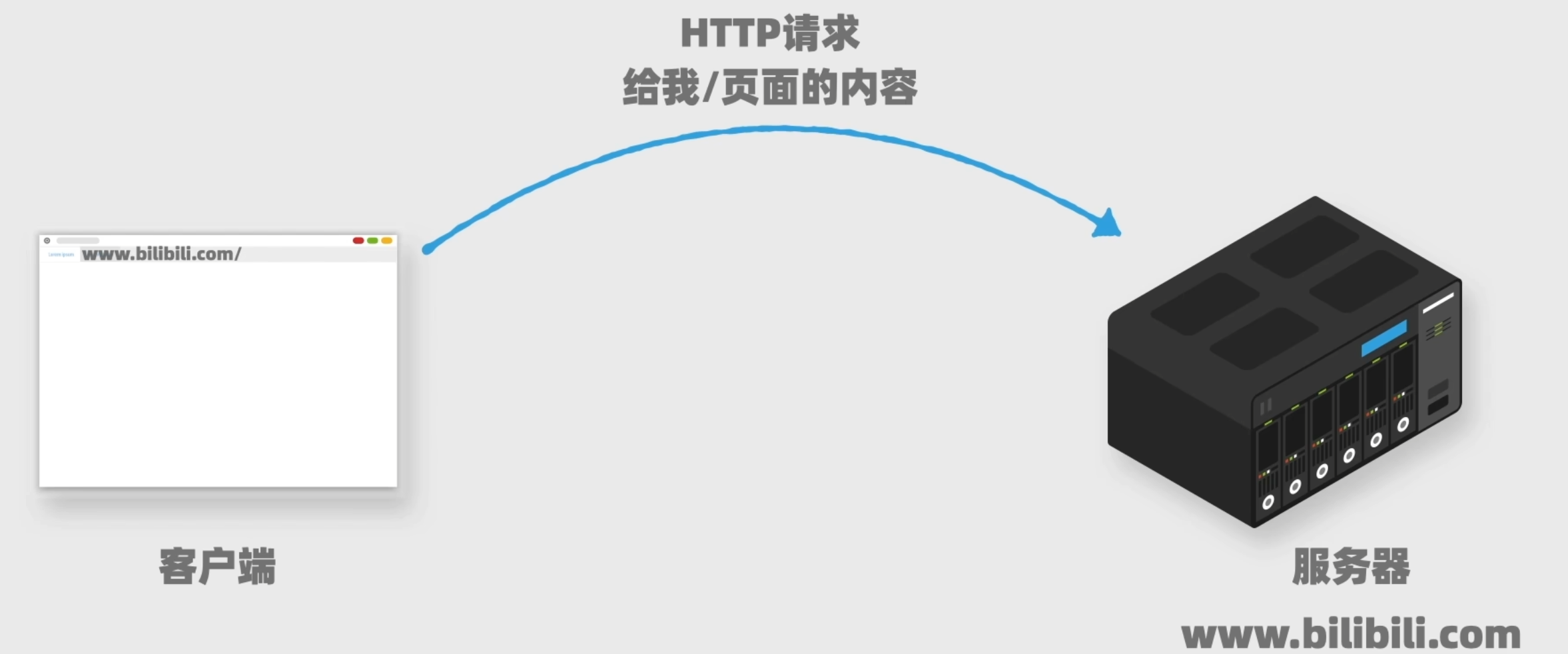
HTTP实际上有不同的请求方法,最常见的是GET和POST
- GET:主要用于获取数据,爬虫最常用于这个
- POST:用于创建数据
比如说我们进入一个网页,浏览器会发送GET请求,得到网页内容;当我们提交账号注册表单时,浏览器会发送一个POST请求,把你的用户名、密码等信息放到请求主题里,给到服务器。
完整的HTTP请求
完整的HTTP请求就只有三个:请求行、请求头、请求体三大部分
1 | POST /user/info HTTP/1.1 请求行 方法类型 资源路径 协议版本 |
完整的HTTP响应
当服务器接收到HTTP请求后,它会根据所有这些信息,返回HTTP响应。响应也由三个部分组成:状态体、响应头、响应体
1 | 200 OK 状态行 协议版本 状态码 状态消息 |
那么我们如何通过Python去构建和发送一个HTTP请求呢,又要如何获取HTTP相应呢?
如何用Python Requests发送HTTP请求
安装Requests库
Python的Requests库让我们可以通过Python代码去构建和发送HTTP请求,由于这个库是第三方库,并不是Python自带的,我们要先安装它,在终端内输入这个即可安装
1 | pip install requests |
如果显示Successfully installed requests的话,那么就是安装成功;
如果显示already satisfied的话,那么就是已经安装过
requests.get发送请求
1 | import requests |
运行结果为:
1 | <Response [200]> |
可以看出response是一个Response类的实例,代表着服务器发送给我们的响应。
响应码
响应实例包含的属性有status_code,表示为响应码。
- 状态码=200:请求成功
- 状态码=404:检查传入的URL是不是有问题,资源不存在
我们可以通过状态码来判断成没成功:
1 | import requests |
但是这样有点繁琐,所以我们可以使用Response类的ok属性。
1 | import requests |
获取响应内容
如果我们想要获取相应内容,Response类的text属性会以字符串储存响应内容:
1 | import requests |
输出结果将会为网页的源码,也就是HTML
请求头headers
headers是requests.get函数的一个参数,它的数据类型是字典,它的各个键值对就对应着我们要传入的请求头,就像我们上面所说的那样,它本意就是请求头内容。如果我们不在get函数中输入headers参数,那么程序将会自动设置。但我们有些时候需要让python程序伪装成浏览器来进行爬取,所以我们需要更改headers参数里面的User-Agent。
1 | import requests |
如何用Python Requests拿到豆瓣源码
豆瓣网站并不支持Python程序来直接访问,所以我们需要浏览器的User-Agent来进行访问。那么如何得到自己浏览器的User-Agent呢?
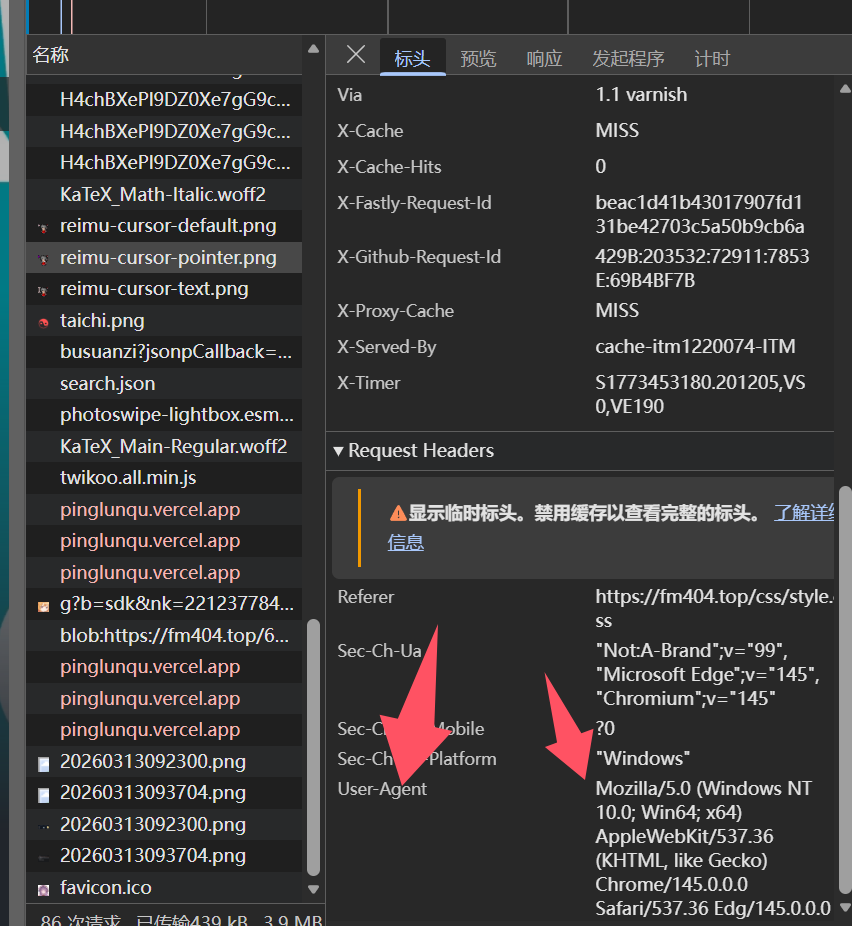
我们先随便打开一个网站,然后右键空白处点击检查。
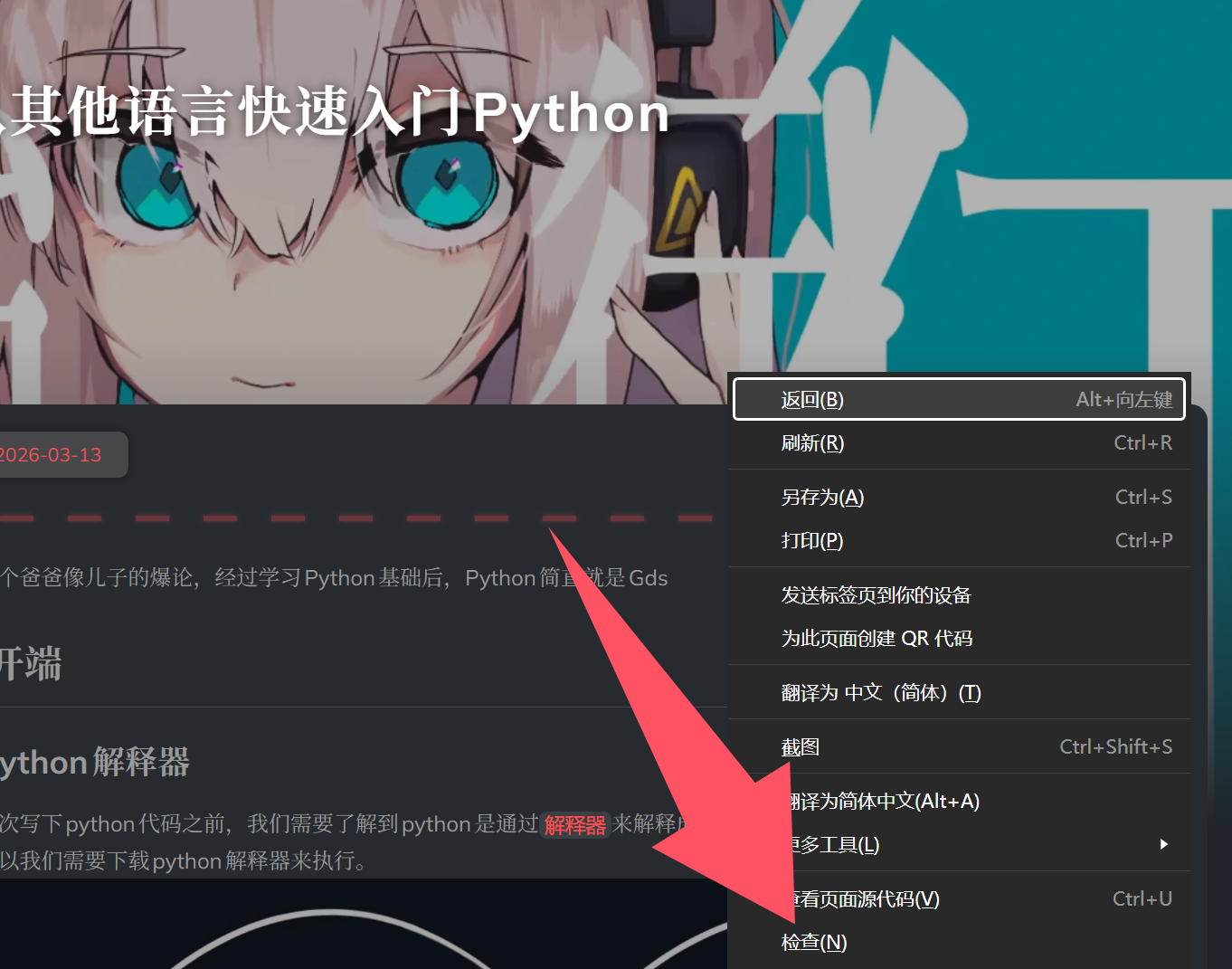
接着进入Network,也就是网络
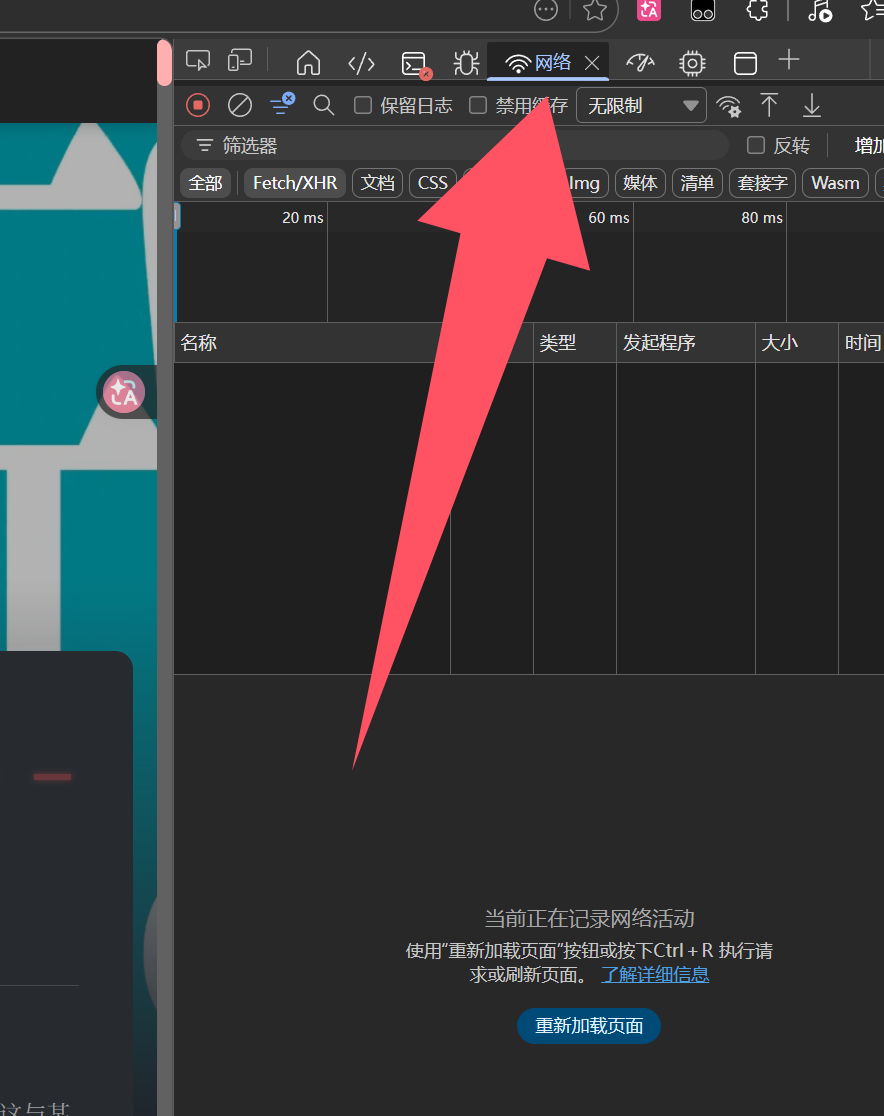
接着按下F5刷新页面,就能看到浏览器发送的所有HTTP请求。我们随便打开一个请求,然后打开它的Header也就是标头,来看看里面一个叫做User-Agent的属性,它就是我们想要的浏览器User-Agent。
获取源代码
接着我们来获取豆瓣源代码,编写python代码:
1 | import requests |
这样就会响应成功
HTML
什么是HTML?
一个网页有三大技术要素,HTML,CSS,JavaScript
- HTML:定义了网页的结构和信息
- CSS:定义网页的样式
- JavaScript:定义了用户和网页的交互逻辑
我们爬虫最关注的是网页信息,所以一般只跟HTML打交道,一个最最简单的HTML长这样:
1 |
|
每个被尖括号包围的都是一个HTML标签,最开头的<!DOCTYPE HTML>用来告知浏览器这个文件类型是HTML。而尖括号开头和结尾分别是起始标签和闭合标签,他们中间的内容一般被称之为元素我们现在来里面填充内容:
1 |
|
body表示的是文档的主体内容,html整个页面东西都要放里面,h1表示一级标题,p表示一个段落。那么我们就说h1元素和p元素都是body元素的子元素,而h1和p之间又是兄弟元素。
HTML常见标签
标题
- h1:一级标签
- h2:二级标签
- h3:三级标签
- h4:四级标签
文本段落
- p
换行标签
- br
加粗
- b
斜体
- i
下划线
- u
图片
1 | <img src="图片URL或者路径" width="宽度" height="高度"> |
链接
1 | <a href="https://fm404.top">我的主页</a> |
容器
- div:块级容器,独占自己的一块区域,一行最多放一个div元素
- span:内联容器,不会独占一块,一行可以有多个span元素
有序列表
- ol:表示列表
- li:列表内元素
1 | <ol> |
运行样式
1 | 1.博士 |
无序列表
- ul:表示列表
- li:列表内元素
1 | <ul> |
运行样式
1 | · 博士 |
表格
- table:定义表格标签
- thead:表格头部,一般是表格第一行
- tbody:表示表格的主体
- tr:定义表格行
- td:表格行内的单元格
1 | <table> |
运行样式
1 | 表头1 表头2 |
我们可以为table加上一些属性
- border:表格边框
class属性
这个属性可被用在所有元素上,定义元素的类的名称。类可以帮助我们分组,比如说一个网页上可能有多个文本段落:
1 | <p class="content">给岁月以文明</p> |
那么我们可以通过class = "content和class = "review"来区分哪些文本段落是文章,哪些文本段落是用户评论
如何用Beautiful Soup来解析HTML内容
我们首先要知道BeautifulSoup是bs4库内的一个供我们用来解析的类
老规矩第三方库先安装
1 | pip install bs4 |
接着开始写代码
1 | from bs4 import BeautifulSoup |
接着BeautifulSoup会把看似复杂的HTML内容解析成如下图的树状结构,让搜索和修改HTML结构变得更加容易:
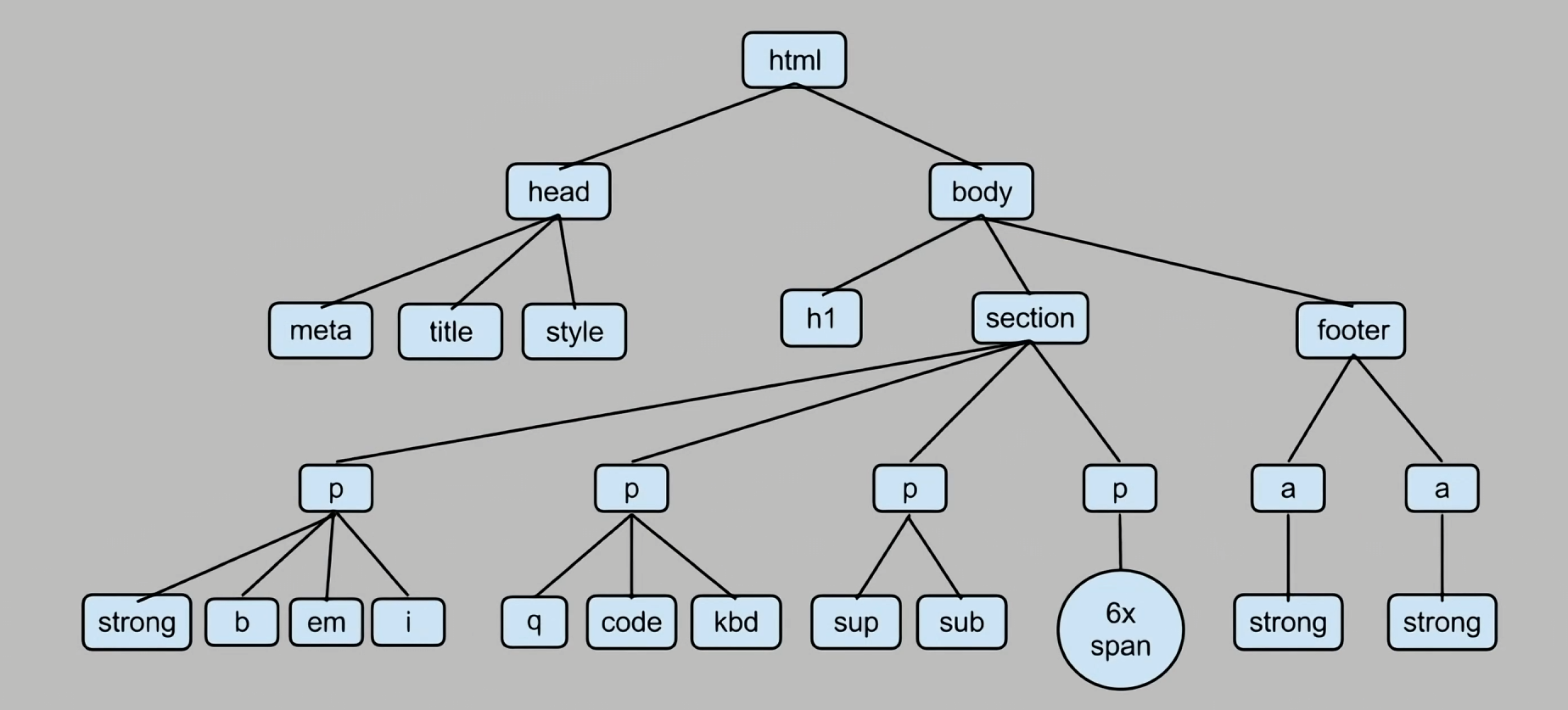
我们要知道对象有方法和属性,这个soup对象就有非常多的方法和属性。如果我们的html有多个p标签,那么我们输入print(soup.p)将会获得第一个p标签。
1 | <p>内容<\p> |
获取所有书的价格
但我们不是想要找到第一个类型元素,比如我们要爬取书籍网站,就是要爬取网页上所有的书名和价格,这该怎么办呢?这个时候我们就要分析下想要信息的特点,浏览器的检查功能就很好用了。
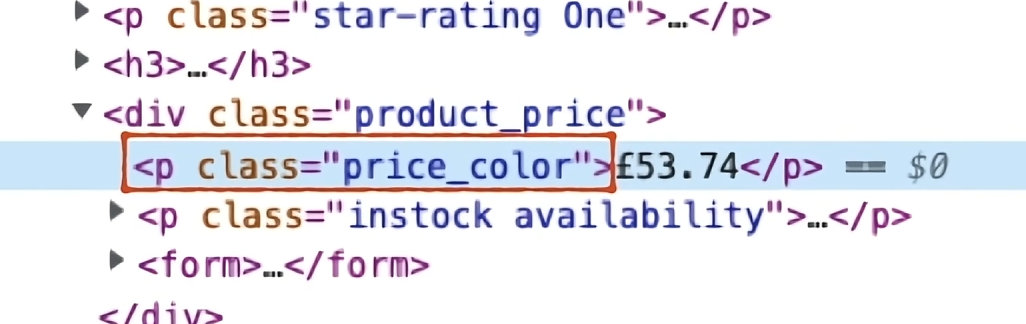
比如在这个网站里,所有价格标签p中都会有一个class属性为price_color。
1 | from bs4 import BeautifulSoup |
1 | <p class="price_color">£51.77</p> |
但还有一个问题是,如果我们只想要数字那么该怎么办呢?我们可以打印对象的string值
1 | from bs4 import BeautifulSoup |
1 | £51.77 |
如果我们不想要这个价格标签那么该怎么办呢?我们可以通过切片操作来进行
1 | print(price.string[2:]) |
就是打印字符串索引2开始的后面字符
获取所有书名
获取书名这个有点难搞,因为我们会发现这些书名并没有什么公共的class属性之类的

那么我们换个角度去找共性,我们会发现都是h3标题的子元素。
1 | from bs4 import BeautifulSoup |
1 | A Light in the ... |
爬虫实战-获取豆瓣电影top 250的所有标题
安装上面的步骤来做即可
1 | from bs4 import BeautifulSoup |
运行结果
1 | 肖申克的救赎 / The Shawshank Redemption / 月黑高飞(港) / 刺激1995(台) |
爬虫实践-获取豆瓣电影TOP 250所有电影内容
1 | from bs4 import BeautifulSoup |
1 | ----------------------------------------------------------------- |

说些什么吧!