
走进JAVA IO
底层
注意: 这块会涉及到操作系统和计算机组成原理相关内容。
I/O简而言之,就是输入输出,其实I/O无时无刻都在我们的身边,比如读取硬盘上的文件,网络文件传输,鼠标键盘输入,也可以是接受单片机发回的数据,而能够支持这些操作的设备就是I/O设备。
我们可以大致看一下整个计算机的总线结构:
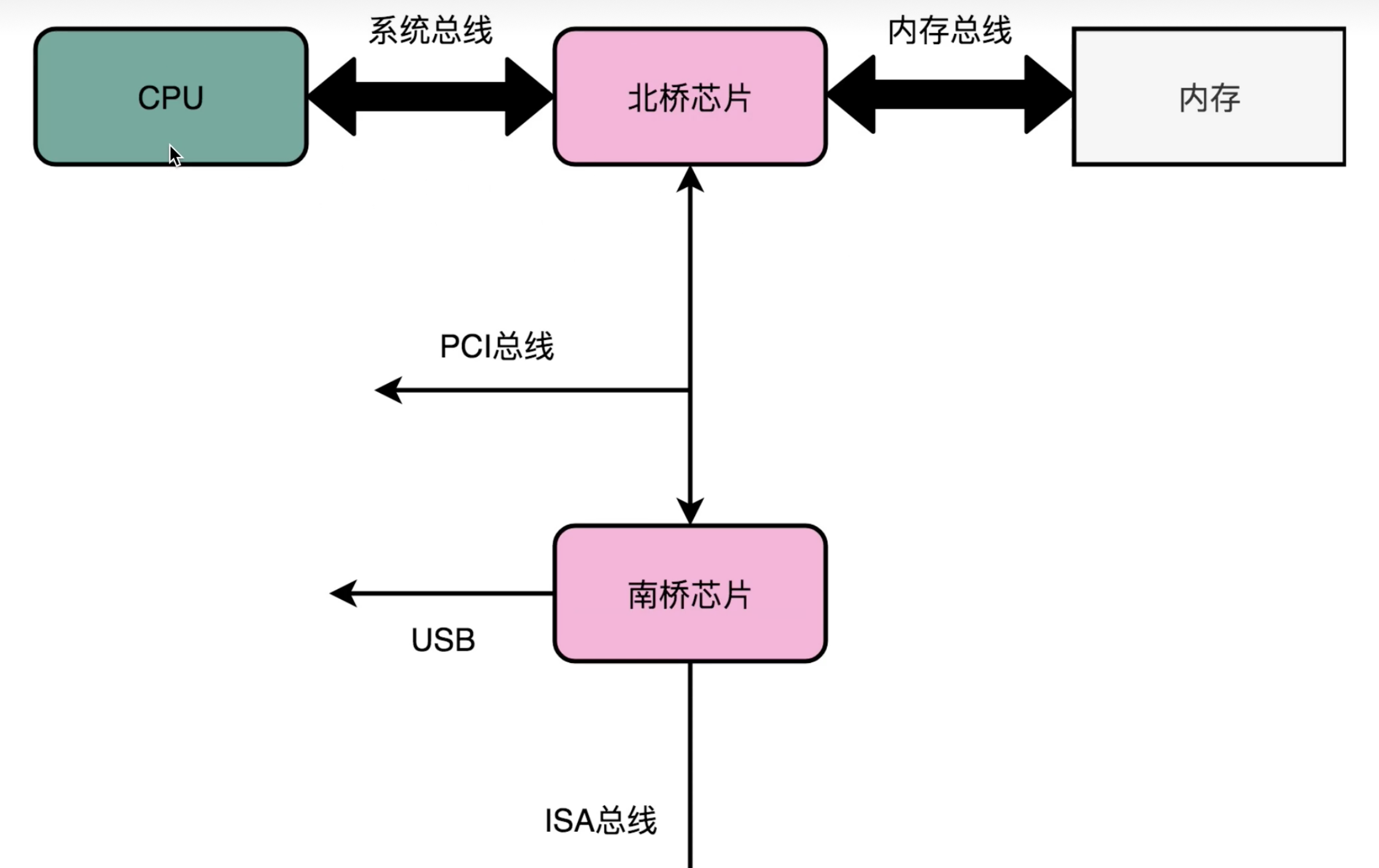
不过基本现在北桥芯片都在CPU里面了。
常见的I/O设备一般是鼠标、键盘这类通过USB进行传输的外设或者是通过Sata接口或是M.2连接的硬盘。一般情况下,这些设备是由CPU发出指令通过南桥芯片间接进行控制,而不是由CPU直接操作。

上面的这些USP即可偶就是插入IO设备。
而我们在程序中,想要读取这些外部连接的I/O设备中的内容,就需要将数据传输到内存中。而需要实现这样的操作,单单凭借一个小的程序是无法做到的,而操作系统(如:Windows/Linux/MacOS)就是专门用于控制和管理计算机硬件和软件资源的软件,我们需要读取一个IO设备的内容时,就可以向操作系统发出请求,由操作系统帮助我们来和底层的硬件交互以完成我们的读取/写入请求。
从读取硬盘文件的角度来说,不同的操作系统有着不同的文件系统(也就是文件在硬盘中的存储排列方式,如Windows就是NTFS、MacOS就是APFS),硬盘只能存储一个个0和1这样的二进制数据,至于0和1如何排列,各自又代表什么意思,就是由操作系统的文件系统来决定的。
从网络通信角度来说,网络信号通过网卡等设备翻译为二进制信号,再交给系统进行读取,最后再由操作系统来给到程序。
JDK的IO框架
JDK提供了一套用于IO操作的框架,为了方便我们开发者使用,就定义了一个像水流一样,根据流的传输方向和读取单位,分为字节流InputStream和OutputStream以及字符流Reader和Writer的IO框架。这里的流指的是数据流,通过流,我们就可以一直从流中读取数据,直到读取到尽头,或是不断向其中写入数据,直到我们写入完成,而这类IO就是我们所说的BIO。
字节流一次读取一个字节,也就是一个byte的大小,而字符流顾名思义,就是一次读取一个字符,也就是一个char的大小(在读取纯文本文件的时候更加适合)
FileInputStrea文件字节流
相对路径和绝对路径
1 | C://User/lbw/nb 这个就是一个绝对路径,因为是从盘符开始的 |
读取文件FileInputStream
IO异常
要学习和使用IO,首先就要从最易于理解的读取文件开始说起。
首先介绍一下FileInputStream,我们可以通过它来获取文件的输入流:
1 | public static void main(String[] args) { |
IO操作一般都需要对异常进行处理,因为可发生异常太多了,比如网卡了导致网络IO出现问题,或者本地文件被占用了无法读取之类的,它抛出来的异常大部分都是编译时异常。
在使用完成一个流之后,必须关闭这个流来完成对资源的释放,否则资源会被一直占用:
1 | public static void main(String[] args) { |
try-with-resource语法
虽然这样的写法才是最保险的,但是显得过于繁琐了。在JDK1.7新增了try-with-resource语法,用于简化这样的写法(本质上还是和这样的操作一致,只是换了个写法):
1 | public static void main(String[] args) { |
read读取
现在我们拿到了文件的输入流,那么怎么才能读取文件里面的内容呢?我们可以使用read方法:
1 | public static void main(String[] args) { |
这里的read读出来是一个字节,为ASCII码,所以类型是int
使用read可以直接读取一个字节的数据,注意,流的内容是有限的,读取一个少一个。我们如果想一次性全部读取的话,可以直接使用一个while循环来完成:
1 | public static void main(String[] args) { |
available查看剩余可读字节
使用available方法能查看当前可读的剩余字节数量(注意:并不一定真实的数据量就是这么多,尤其是在网络I/O操作时,这个方法只能进行一个预估也可以说是暂时能一次性可以读取的数量,当然在磁盘IO下,一般情况都是真实的数据量)
1 | try(FileInputStream inputStream = new FileInputStream("test.txt")) { |
当然,一个一个读取效率太低了,那能否一次性全部读取呢?我们可以预置一个合适容量的byte[]数组来存放:
1 | public static void main(String[] args) { |
inputStream.read(bytes):
- 将文件中的字节数据一次性读取到字节数组
bytes中,返回值是实际读取的字节数。
System.out.println(new String(bytes)); new String(bytes):将字节数组按照默认字符编码(如 UTF-8/GBK) 转换为字符串。- 因为
bytes数组中存放的是hello对应的字节(h->104,e->101,l->108,l->108,o->111),所以转换后控制台会打印hello。
也可以控制要读取数量:
1 | System.out.println(inputStream.read(bytes, 1, 2)); //第二个参数是从给定数组的哪个位置开始放入内容,第三个参数是读取流中的字节数 |
注意:一次性读取同单个读取一样,当没有任何数据可读时,依然会返回-1
skip跳过指定数量的字节,返回值为实际跳过的字节
通过skip()方法可以跳过指定数量的字节,返回值为实际跳过的字节:
1 | public static void main(String[] args) { |
输出文件FileOutputStream
既然有输入流,那么文件输出流也是必不可少的:
1 | public static void main(String[] args) { |
write方法
1 | public static void main(String[] args) { |
这个write写入是覆盖写入,那么有没有什么办法可以在后面追加写入呢?有的兄弟,有的:
1 | public static void main(String[] args) { |
注意上面的true,就是开启了追加模式。还有就是,这里的覆盖和清空源文件,是FileOutputStream outputStream = new FileOutputStream(“output.txt”)这行代码运行后立马清空的,如果已经清空后多次write的清空下并不会清空,而是追加
flush方法
缓存区的设计本意是提速,不是拖慢速度
因为 CPU 操作内存(缓存区在内存里)的速度,比 CPU 操作磁盘快成千上万倍。如果每写 1 个字节就直接刷到磁盘,CPU 要等磁盘慢吞吞处理完才能继续,这才是真的拖慢速度;
缓存区就是先把数据攒在内存里,等攒够了(缓存区满 / 程序主动 flush / 流关闭),再一次性写入磁盘,减少磁盘 IO 次数,反而提速。flush 是 “把缓存区里已有的数据,立刻写入磁盘”,但不会关闭流(流还能继续写);而如果不主动 flush,程序也会在两种情况下自动刷:①缓存区满了;②流被关闭时(比如 try-with-resources 结束时)。
拷贝文件
利用输入流和输出流,就可以轻松实现文件的拷贝了:
1 | public static void main(String[] args) { |
FileReader文件字符流
FileReader读入数据
字符流不同于字节,字符流是以一个具体的字符进行读取,因此它只适合读纯文本的文件,如果是其他类型的文件不适用:
1 | public static void main(String[] args) { |
同理,字符流只支持char[]类型作为存储:
1 | public static void main(String[] args) { |
FileWriter写入数据
既然有了Reader肯定也有Writer:
1 | public static void main(String[] args) { |
File类
这里需要额外介绍一下File类,它是专门用于表示一个文件或文件夹,只不过它只是代表这个文件,但并不是这个文件本身。通过File对象,可以更好地管理和操作硬盘上的文件。
1 | public static void main(String[] args) { |
通过File对象,我们就能快速得到文件的所有信息,如果是文件夹,还可以获取文件夹内部的文件列表等内容:
1 | File file = new File("/"); |
如果我们希望读取某个文件的内容,可以直接将File作为参数传入字节流或是字符流:
1 | File file = new File("test.txt"); |
(Java 7/8/11) 文件工具File类
Files类是java.nio.file包中的一个实用类,在Java 7中推出,提供了许多静态方法(比之前的那个方法多多了,毕竟是个工具类),用于文件和目录的操作。它大大简化了文件处理的工作,例如创建、删除、读取、写入和属性管理等。比如之前的创建目录操作:
1 |
|
path类
其中提供了非常方便的方法直接创建目录,只不过此工具类的路径需要配合Path对象来指定,不能传入字符串路径,它代表一个文件路径,可以直接通过of方法来创建。
1 |
|
path.toAbsolutePath相对路径转换为绝对路径
delete删除
现在回到Files类,对于文件的删除也是很方便的:
1 |
|
在目录有文件的情况下delete目录是会报错的,上面的File也是这样的
快捷操作
1 |
|
find方法
此外,对于文件的查找,该工具类也给了非常好用API,其中find方法可以帮助我们快速查找文件:
1 |
|
这里的path类似于遍历每个文件,每个都会运行下面的代码。attributes是给一些限制属性,不需要的话用下划线即可_
walk方法
在Java8之后,Files也为我们提供了很方便的walk方法,它同样是返回一个Stream给我们,其中包含遍历的每一个文件的Path对象,这样就简单多了:
1 |
|
BufferdInputStream缓冲流
BufferdInputStream操作
由于外部I/O设备的速度一般都达不到内存的读取速度,很有可能造成程序反应迟钝。而缓冲流正如其名称一样,它能够提供一个缓冲,提前将部分内容存入内存(缓冲区)在下次读取时,如果缓冲区中存在此数据,则无需再去请求外部设备。同理,当向外部设备写入数据时,也是由缓冲区处理,而不是直接向外部设备写入。
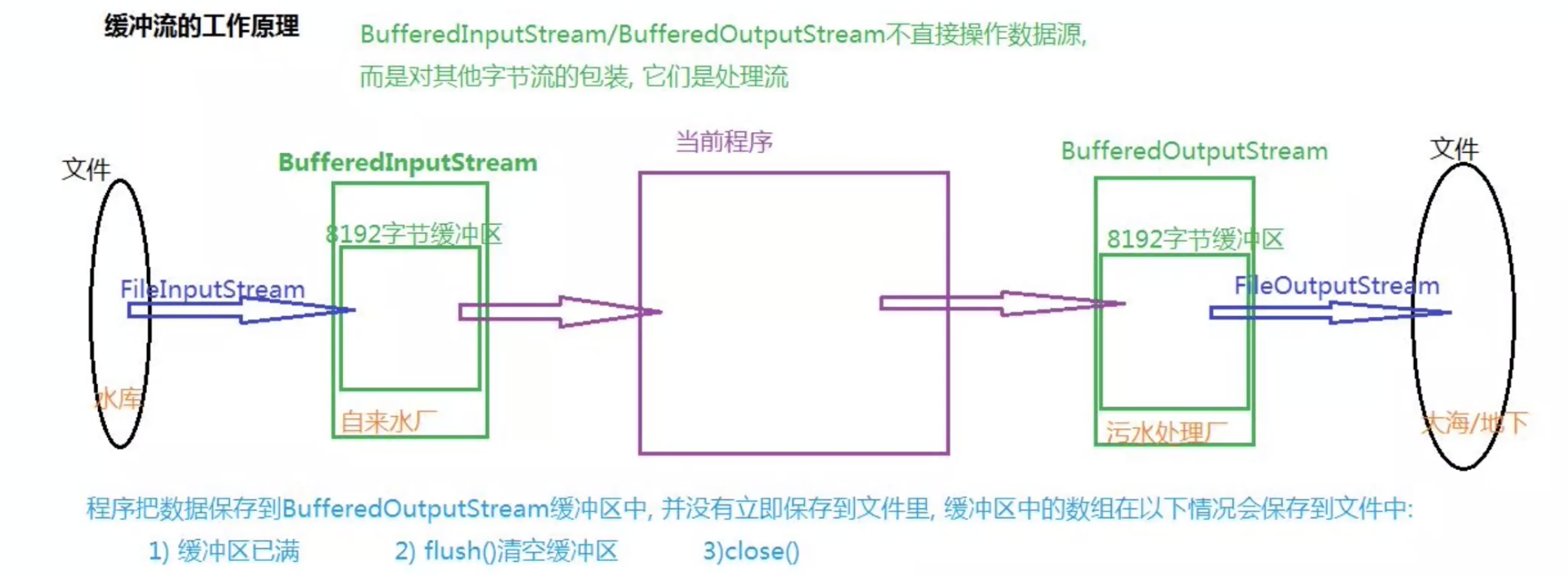
要创建一个缓冲字节流,只需要将原本的流作为构造参数传入BufferedInputStream即可:
1 | public static void main(String[] args) { |
实际上进行I/O操作的并不是BufferedInputStream,而是我们传入的FileInputStream,而BufferedInputStream虽然有着同样的方法,但是进行了一些额外的处理然后再调用FileInputStream的同名方法,这样的写法称为装饰者模式。实际上这种模式是父类FilterInputStream提供的规范,后面我们还会讲到更多FilterInputStream的子类。
我们可以发现在BufferedInputStream中还存在一个专门用于缓存的数组:
1 | /** |
mark()和reset()方法-存档与读档
BufferedInputStream支持reset()和mark()操作,首先我们来看看mark()方法的介绍:
1 | /** |
当调用mark()之后,输入流会以某种方式保留之后读取的readlimit数量的内容,当读取的内容数量超过readlimit则之后的内容不会被保留,当调用reset()之后,会使得当前的读取位置回到mark()调用时的位置。
1 | public static void main(String[] args) { |
我们读取文件的时候总是一个字节或者一个字符地来读,读过就没了。而mark可以让我们设计一个标记点,接着通过reset函数来进行读档行为,没错,其实就是和存档读档差不多,可以从新从那儿开始存入缓冲区。不过这里mark保存机制是你当前读到的单词从0开始计算,也就是说你mark(1)的话就是存档点在这个单词后。
readlimit
readlimit 并不是 “只保留 N 个字符” 的意思,它的官方定义是:
调用
mark()后,在调用reset()之前,允许从输入流中读取的最大字节数。如果读取的字节数超过这个值,那么后续调用reset()可能会失败(不是一定会失败)。
mark() 实际保留的字节数 = max(readlimit, 缓冲区大小)
1 | public static void main(String[] args) { |
BufferedOutputSteam
了解完了BufferedInputStream之后,我们再来看看BufferedOutputStream,其实和BufferedInputStream原理差不多,只是反向操作:
1 | public static void main(String[] args) { |
缓冲字符流
既然有缓冲字节流,那么肯定也有缓冲字符流,缓冲字符流和缓冲字节流一样,也有一个专门的缓冲区,BufferedReader构造时需要传入一个Reader对象:
1 | public static void main(String[] args) { |
相比Reader更方便的是,它支持按行读取:
1 | public static void main(String[] args) { |
读取后直接得到一个字符串,当然,它还能把每一行内容依次转换为集合类提到的Stream流:
1 | public static void main(String[] args) { |
它同样也支持mark()和reset()操作:
1 | public static void main(String[] args) { |
BufferedReader处理纯文本文件时就更加方便了,BufferedWriter在处理时也同样方便:
1 | public static void main(String[] args) { |
OutputStreamWriter转换流
有时会遇到这样一个很麻烦的问题:我这里读取的是一个字符串或是一个个字符,但是我只能往一个OutputStream里输出,但是OutputStream又只支持byte类型,如果要往里面写入内容,进行数据转换就会很麻烦,那么能否有更加简便的方式来做这样的事情呢?
1 | public static void main(String[] args) { |
同样的,我们现在只拿到了一个InputStream,我们就可以使用InputStreamReader来帮助我们实现:
1 | public static void main(String[] args) { |
InputStreamReader和OutputStreamWriter本质也是Reader和Writer,因此可以直接放入BufferedReader来实现更加方便的操作。是可以缓冲套缓冲的哦
PrintStream打印流
System.out开盒
孩子们,我们终于可以知道一个和牛逼的事情了,就是System.out到底是个什么东西👽
PrintStream也继承自FilterOutputStream类因此依然是装饰我们传入的输出流,但是它存在自动刷新机制,例如当向PrintStream流中写入一个字节数组后自动调用flush()方法。PrintStream也永远不会抛出异常,而是使用内部检查机制checkError()方法进行错误检查。最方便的是,它能够格式化任意的类型,将它们以字符串的形式写入到输出流。
System.out也是PrintStream,不过默认是向控制台打印,我们也可以让它向文件中打印:
1 | public static void main(String[] args) { |
我们平时使用的println方法就是PrintStream中的方法,它会直接打印基本数据类型或是调用对象的toString()方法得到一个字符串,并将字符串转换为字符,放入缓冲区再经过转换流输出到给定的输出流上。

因此实际上内部还包含这两个内容:
1 | /** |
Scanner开盒
而我们之前使用的Scanner,使用的是系统提供的输入流:
1 | public static void main(String[] args) { |
我们也可以使用Scanner来扫描其他的输入流:
1 | public static void main(String[] args) throws FileNotFoundException { |
相当于直接扫描文件中编写的内容,同样可以读取。
Scanner 是在输入流(InputStream)基础上封装的高级工具类,可以把它理解成:
- 单纯的 read:像用手从水管里接水,只能一滴一滴(按字节)接,拿到的是原始的 “水”(字节),需要自己处理;
- Scanner:像用带过滤 / 分装功能的水杯接水,它先帮你把 “水”(字节)转换成字符,还能按 “行、数字、空格分隔的内容” 等规则拆分,直接拿到你想要的格式。
1 | try (Scanner scanner = new Scanner(new FileInputStream("艾斯比小污.txt"), "UTF-8")) { |
DataInputStream数据流
读取
数据流DataInputStream也是FilterInputStream的子类,同样采用装饰者模式,最大的不同是它支持基本数据类型的直接读取:
1 | public static void main(String[] args) { |
举个例子就是:
1 | int num = dis.readInt(); // 一次性读 4 个字节 → 组装成 int |
写入
用于写入基本数据类型:
1 | public static void main(String[] args) { |
注意,写入的是二进制数据,并不是写入的字符串,使用DataInputStream可以读取,一般他们是配合一起使用的。
ObjectOutputStream对象流
既然基本数据类型能够读取和写入基本数据类型,那么能否将对象也支持呢?ObjectOutputStream不仅支持基本数据类型,通过对对象的序列化操作,以某种格式保存对象,来支持对象类型的IO,注意:它不是继承自FilterInputStream的。
1 | public static void main(String[] args) { |
如果是你自己写的类的话,必须要实现Serializable接口才能被序列化。接着如果你要打印的对象的话,记住一件事:
System.out.println() 会自动调用 toString()
System.out.println() 在打印对象时,会自动调用该对象的 toString() 方法:
- 如果重写了 → 输出你定义的字符串
- 如果没重写 → 输出默认的 “类名 @哈希码”
类的版本号seriaVersionUID
在我们后续的操作中,有可能会使得这个类的一些结构发生变化,而原来保存的数据只适用于之前版本的这个类,因此我们需要一种方法来区分类的不同版本:
1 | static class People implements Serializable{ |
如果已经保存到类为114514版本,那么你修改类后再进行读取会报错。
选择性保存transient
一个类有多个属性,我们保存的时候只想保存特定的属性,那么该怎么弄呢?很简单,添加一个transient的关键词就行了:
1 | public static void main(String[] args) { |
其实我们可以看到,在一些JDK内部的源码中,也存在大量的transient关键字,使得某些属性不参与序列化,取消这些不必要保存的属性,可以节省数据空间占用以及减少序列化时间。
ByteArrayInputStream字节数组流
这个流是一个非常特殊的流,它内部维护了一个byte[]类型的对象,用于直接包含流的数据。
1 | public static void main(String[] args) throws IOException { |
通过构造ByteArrayInputStream来快速将我们需要的数据构造为流,它接受一个byte[]数组,此数组将直接作为其数据,当对流的数据进行读取时,直接返回数据中的内容。
与之相反的有一个叫ByteArrayOutputStream的流,它内部同样维护一个byte[]数组,用于存放外部写入的数据,在写入数据完成后,我们可以调用toByteArray来获取其中的数据:
1 | public static void main(String[] args) throws IOException { |
这两种流在处理一些直接数据时非常方便。
(Java 9/11/12) 输入流快捷操作
readAllBytes内容读取
之前我们如果需要读取一个文本文件的内容,需要写一个循环来不断read里面的内容,直到结束,这实在是太繁琐了,通过available()获取的剩余容量又不一定准确。所以,从Java 9 开始,官方内置一个新的方法来便于我们一次性读取文件内容,我们终于可以解放双手了:
1 | try (InputStream stream = new FileInputStream("./hello.txt")) { |
注意如果流已经被读取完成,调用此方法只能直接返回空数组,因为没数据可读了。
readNBytes方法-指定数量
要读取指定数量的数据怎么办呢?我们有readNBytes方法,它可以更灵活地控制读取流中的多少字节或是哪个位置开始的字节:
1 | try (InputStream stream = new FileInputStream("./hello.txt")) { |
注意readNBytes返回值为实际读取的字节数,因为有可能出现流中数据还没有想要的这么长的情况。
skipNBytes更精准的跳过
它不像skip()那样跳过多少算多少,而是要求必须跳过这么多字节,否则抛出EOFException异常,比如:
1 | try (InputStream stream = new ByteArrayInputStream("再见,在群星见".getBytes())) { |
生成已读取结束流
Java 11还为我们提供了一个直接生成已读取结束的流的方法:
1 | try (InputStream stream = InputStream.nullInputStream()) { //直接生成一个没有数据的等价于用完的流 |
类似的还有OutputStream的nullOutputStream方法,生成一个可以无限倾倒数据的输出流,就像给黑洞吞了就没了。你没有给它设置输出文件,当然就直接吞掉了你的数据。
tranfetTo 数据转移流
transferTo,它可以直接将当前输入流中的内容转换到一个输出流中,相当于用一个管道直接把输入输出连接起来,输入的内容直接往输出的地方跑。这就很方便了,比如我们要拷贝一个文件,可以直接使用:
1 | try (InputStream in = new FileInputStream("./hello.txt"); |
这样,一个文件拷贝就轻松实现了。

说些什么吧!